27 Jan 2022
|
TIL
학습과정
1. 자바의 정석
컬렉션 프레임웍 부분 공부를 마무리 했다.
- HashSet, TreeSet
- HashMap과 HashTable
- TreeMap
- Properties
- Collections
2. 알고리즘
bronze 1. 설탕 배달 문제와 silver 5. 30 문제를 풀었다.
- 설탕 배달 문제 같은 경우, 난이도가 많이 어렵지 않아 빠르게 풀 수 있었다.
- 30 문제의 경우, 아이디어도 빠르게 떠오르고 구현하는데도 오래 걸리지 않았지만 Replit에서는 잘 실행됐지만, 백준에 제출했을 때 RuntimeError가 떴다. 아직 에러 발생 원인을 찾지 못했다…
- 내일 한 번 더 30 문제를 보면서 에러가 발생한 원인을 찾아봐야겠다.
26 Jan 2022
|
운영체제
CS
KOCW에 공개된 이화여대 반효경 교수님 운영체제 강의 수강 후 정리한 내용입니다.
2가지 주소
- Logical address (=virtual address)
- 프로세스마다 독립적으로 가지는 주소 공간
- 각 프로세스마다 0번지부터 시작
- CPU가 보는 주소는 logical address
- Physical address
- 주소 바인딩: 어떤 프로그램이 어디 메모리 주소로 올라갈지를 결정하는 것
- 주소 변환 과정: Symbolic address -> Logical address -> Physical address
- Symbolic address: 프로그래머가 사용하는 주소
1. 주소 바인딩 (Address Binding)
Compile time binding
- 물리적 메모리 주소가 컴파일 시 알려짐
- 시작 위치 변경시 컴파일을 다시 해야 함
- 컴파일러는 절대 코드(absolute code) 생성
Load time binding
- 실행이 시작될 때 물리적 메모리 주소가 알려짐
- 컴파일러가 재배치가능코드(relocatable code)를 생성한 경우 가능
Execution time binding (= Run time binding)
- 실행 도중 물리적 메모리 주소가 변경될 수 있는 binding
- CPU가 주소를 참조할 때마다 binding을 점검 (address mapping table)
-
하드웨어적인 지원이 필요 (ex. base and limit registers, MMU)
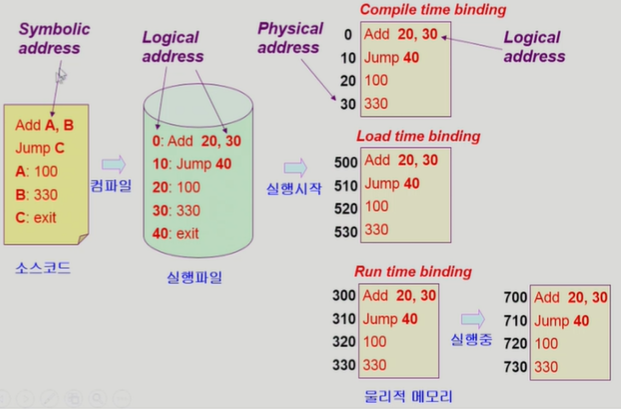
- 소스코드: A+B를 해서 A에 저장한 후 C 위치로 jump
- Compile time binding
- 컴파일 시점에 이미 물리적 메모리 주소가 결정됨
- 실행파일에 있는 주소의 위치와 같은 주소에 위치해야 함
- Load time binding
- 프로그램이 실행되서 메모리에 올라갈 때 물리적 주소가 결정됨
- Run time binding
- Load time binding처럼 프로그램이 실행되서 메모리에 올라갈 때 물리적 주소가 결정되지만, 프로그램 실행 도중 물리적 주소가 변경될 수 있음
- 메모리에서 쫓겨났다가 다시 올릴 때, 300번지에 다른 내용이 들어와있다면 비어있는 700번지에 내용을 저장할 수 있음
MMU (Memory-Management Unit)
- logical address를 physical address로 매핑해주는 하드웨어 장치
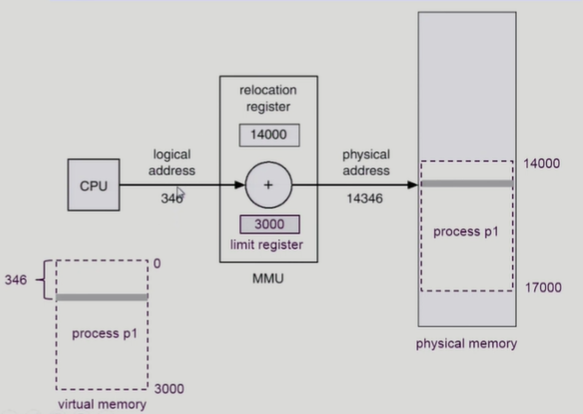
-
MMU scheme
- base register와 limit register를 사용해 주소 변환을 수행
- 사용자 프로세스가 CPU에서 수행되며 생성해내는 모든 주소값에 대해 base register(= relocation register)을 더함
- base register는 접근할 수 있는 물리적 메모리 주소의 최솟값을 가짐
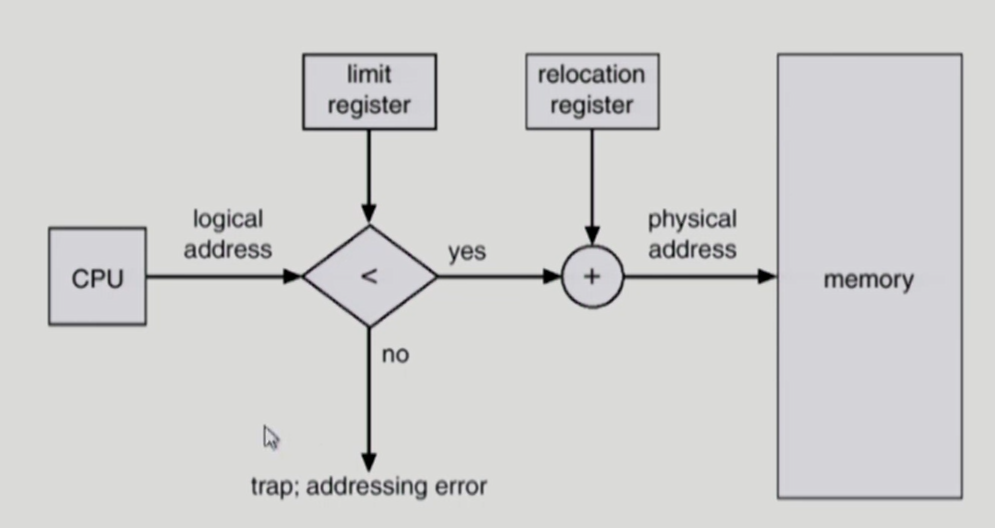
- limit register는 프로그램의 최대 크기를 담고 있음. 프로그램의 논리 주소보다 더 큰 주소의 값을 요청하면 trap이 발생
-
user program
- logical address만을 다루며, 실제 physical address를 볼 수 없고 알 필요가 없음
2. Some Terminologies
Dynamic Loading
- 프로세스 전체를 메모리에 미리 다 올리는 것이 아니라 해당 루틴이 불려질 때 메모리에 load하는 것
- memory utilization 향상
- 가끔식 사용되는 만은 양의 코드의 경우 유용 (ex. 오류 처리 루틴)
- 운영체제의 특별한 지원 없이 프로그램 자체에서 구현 가능 (OS는 라이브러리를 통해 지원 가능)
- 운영체제가 직접 관리하는 페이징 기법과는 다름. 하지만 현재는 dynamic loading과 섞어 사용하기도 함
- 프로그래머가 명시적으로 dynamic loading을 구현한 것이 본래의 dynamic loading이지만, 프로그래머가 명시적으로 구현하지 않고 운영체제가 관리해주는 것도 dynamic loading이라고 섞어 사용하기도 함
Overlays
- 메모리에 프로세스의 부분 중 실제 필요한 정보만을 올림
- 프로세스의 크기가 메모리보다 클 때 유용
- 운영체제의 지원없이 사용자에 의해 구현
- 작은 공간의 메모리를 사용하던 초창기 시스템에서 수작업으로 프로그래머가 구현
- Manual Overlay라고도 함
- 프로그래밍이 매우 복잡
-
운영체제의 지원이 없다는 것에서 Dynamic Loading과 차이점이 있음
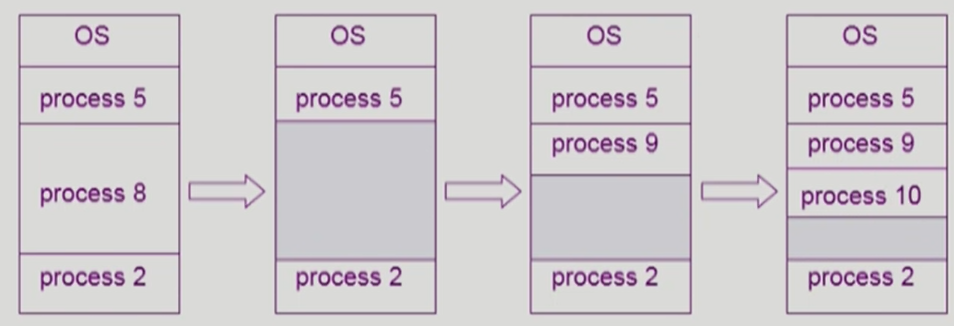
Swappping
- 프로세스를 일시적으로 메모리에서 backing store로 쫓아내는 것
- backing store (= swap area): 디스크. 많은 사용자의 프로세스 이미지를 담을만큼 충분히 빠르고 큰 저장 공간
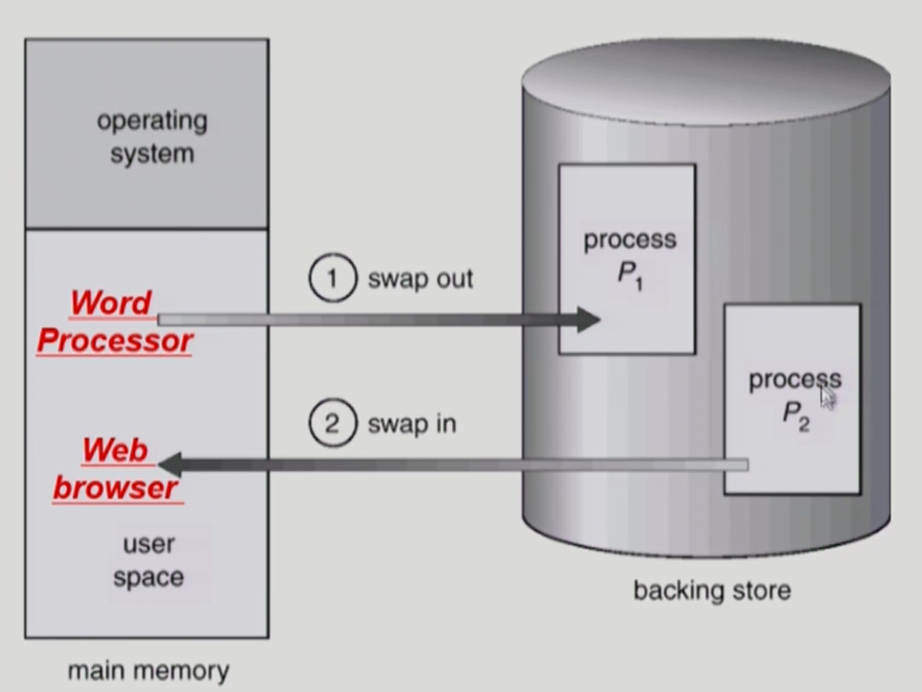
- Swap In / Swap out
- 일반적으로 중기 스케줄러(swapper)에 의해 swap out 시킬 프로세스 선정
- priority-based CPU scheduling algorithm
- priority가 낮은 프로세스를 swapped out 시킴
- priority가 높은 프로세스를 메모리에 올려 놓음
- Compile time 혹은 load time binding에서는 원래 메모리 위치로 swap in 해야 함
- Execution time binding에서는 추후 빈 메모리 영역 아무 곳에나 올릴 수 있음
- swap time은 대부분 transfer time (swap되는 양에 비례하는 시간)
- 원칙적으로 swap in / swap out의 의미는 프로그램를 구성하는 주소 공간 전체가 쫓겨나는 것을 의미하지만 페이징에서 일부 페이지만 쫓겨나는 것을 의미하는 용어로도 사용하기도 함
Dynamic Linking
- Linking을 실행 시간(execution time)까지 미루는 기법
- Linking: 여러 곳에 존재하던 컴파일된 파일들을 하나의 실행 파일로 만드는 과정
Static linking
- 라이브러리가 프로그램의 실행 파일 코드에 포함됨
- 실행 파일의 크기가 커짐
- 동일한 라이브러리를 각각의 프로세스가 메모리에 올리므로 메모리 낭비
Dynamic linking
- 라이브러리가 프로그램의 실행 파일 코드에 포함되지 않고 실행시 연결(link) 됨
- 라이브러리 호출 부분에 라이브러리 루틴의 위치를 찾기 위한 stub이라는 작은 코드를 둠
- 라이브러리가 이미 메모리에 있으면 그 루틴의 주소로 가고 없으면 디스크에서 읽어옴
- dynamic linking을 해주는 라이브러리를 shared library라고 함
- 운영체제의 도움이 필요
3. Allocation of Physical Memory
- 메모리는 일반적으로 두 영역으로 나누어 사용
- OS 상수 영역: interrupt vector와 함께 낮은 주소 영역 사용
- 사용자 프로세스 영역: 높은 주소 영역 사용
사용자 프로세스 영역의 할당 방법
-
Contiguous allocation (연속 할당)
- 각각의 프로세스가 메모리의 연속적인 공간에 적재되도록 하는 것
- 프로그램이 메모리에 올라갈 때 한 군데에 통째로 올라가는 방식
- Fixed partition allocation
- Variable partition allocation
-
Noncontiguous allocation (불연속 할당)
- 하나의 프로세스가 메모리의 여러 영역에 분산되어 올라갈 수 있음
- Paging
- Segmentation
- Paged Segmentation
Contiguous allocation
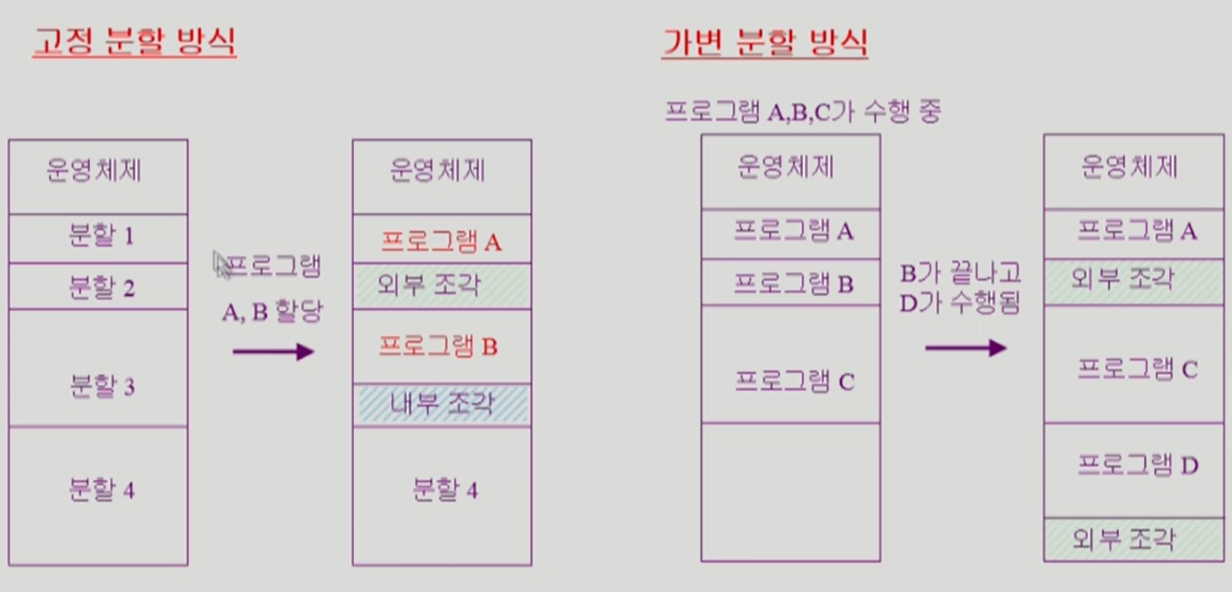
고정 분할 방식 (Fixed partition allocation)
- 물리적 메모리를 몇 개의 영구적 분할(partition)으로 나눔
- 분할의 크기가 동일할 수도 다를 수도 있음
- 분할당 하나의 프로그램을 적재
- External fragmentation(외부 조각): 프로그램 크기보다 분할의 크기가 작은 경우
- 아무 프로그램에도 배정되지 않은 빈 곳인데도 프로그램이 올라갈 수 없는 작은 분할
- Internal fragmentation(내부 조각): 프로그램 크기보다 분할의 크기가 큰 경우
- 하나의 분할 내부에서 발생하는 사용되지 않는 메모리 조각
- 특정 프로그램에 배정되었지만 사용되지 않는 공간
가변 분할 방식 (Variable partition allocation)
26 Jan 2022
|
운영체제
CS
KOCW에 공개된 이화여대 반효경 교수님 운영체제 강의 수강 후 정리한 내용입니다.
1. Deadlock (교착 상태)
- Deadlock: 일련의 프로세스들이 서로가 가진 자원을 기다리며 block된 상태
- Resource (자원)
- 하드웨어, 소프트웨어 등을 포함하는 개념
- ex) IO device, CPU cycle, memory space, semaphore 등
- 프로세스가 자원을 사용하는 절차: Request, Allocate, Use, Release
Deadlock 발생의 4가지 조건
-
Mutual exclusion (상호 배제): 매 순간 하나의 프로세스만이 자원을 사용할 수 있음
-
No preemption (비선점): 프로세스는 자원을 스스로 내놓을 뿐 강제로 빼앗기지 않음
-
Hold and wait (보유대기): 자원을 가진 프로세스가 다른 자원을 기다릴 때 보유 자원을 놓지 않고 계속 가지고 있음
-
Circular wait (순환대기): 자원을 기다리는 프로세스간에 사이클이 형성되어야 함
Deadlock 발생 확인 방법
Resource-Allocation Graph (자원 할당 그래프)
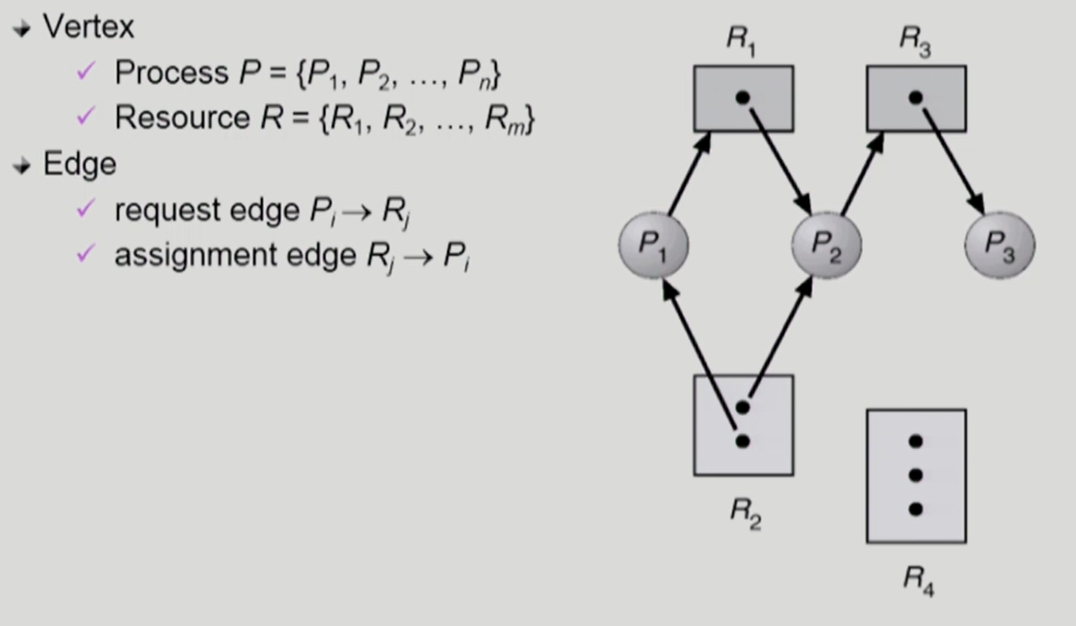
- 동그라미: 프로세스 / 사각형: 자원 / 사각형 안의 점: 자원의 수
- 화살표 종류
- 자원에서 프로세스로 나가는 화살표: 프로세스가 해당 자원을 가지고 있는 상태
- 프로세스에서 자원으로 나가는 화살표: 프로세스가 해당 자원을 요청했지만 아직 획득하지는 못한 상태
- 그래프를 봤을 때, cycle이 없으면 deadlock이 아님
- 그래프에 사이클이 있으면.
- 자원당 인스턴스가 하나 밖에 없다면 (사각형 안의 점이 한 개인 경우), deadlock 발생
- 자원당 인스턴스가 여러 개 있는 경우, deadlock일수도 있고 아닐 수도 있음
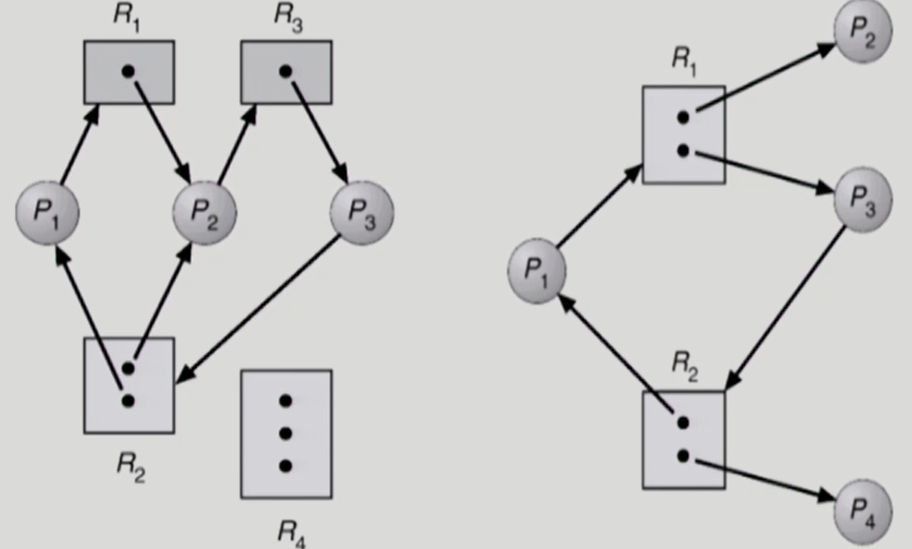
-
왼쪽 그래프의 경우 deadlock 발생
- 자원의 인스턴스가 2개가 있지만, 사이클이 2개가 만들어져 더 이상의 진행이 불가능
- R2의 경우 하나는 P1, 다른 하나는 P2에 있기 때문에, P3가 R2를 요청했을 때 할당할 수 있는 자원이 없기 때문
-
오른쪽 그래프의 경우, 사이클이 있지만 deadlock 발생하지 않음
- P2와 P4는 deadlock과 연관되어 있지 않은 프로세스. P4가 R2의 자원을 쓴 후 반납하면 P3은 R2의 자원을 쓸 수 있기 때문에 deadlock이 발생하지 않음
2. Deadlock의 처리 방법
1. Deadlock Prevention
- 자원 할당 시 Deadlock의 4가지 필요 조건 중 어느 하나가 만족되지 않도록 하는 것
- Utilization 저하, throughput 감소, starvation 문제 발생
Mutual Exclusion: 공유해서는 안되는 자원의 경우 반드시 성립해야 함
Hold and Wait
- 프로세스가 자원을 요청할 때 다른 어떤 자원도 가지고 있지 않아야 함
- 방법 1) 프로세스 시작 시 모든 필요한 자원을 할당받게 하는 방법
- wait할 일이 발생하지 않기 때문에 deadlock이 발생하지 않음
- 자원의 비효율성이 생김
- 방법 2) 자원이 필요할 경우 보유 자원을 모두 놓고 다시 요청
No preemption
- process가 어떤 자원을 기다려야 하는 경우 이미 보유한 자원이 선점됨
- 모든 필요한 자원을 얻을 수 있들 때 그 프로세스는 다시 시작됨
- State를 쉽게 save하고 restore할 수 있는 자원에서 주로 사용 (CPU, memory)
Circular Wait
- 모든 자원 유형에 할당 순서를 정하여 정해진 순서대로만 자원 할당
- ex) 순서가 3인 자원 R_i를 보유 중인 프로세스가 순서가 1인 자원 R_j을 할당받기 위해서는 우선 R_i를 release해야 함
2. Deadlock Avoidance
- 자원 요청에 대한 부가적인 정보를 이용해서 deadlock의 가능성이 없는 경우에만 자원을 할당
- 시스템 state가 원래 state로 돌아올 수 있는 경우에만 자원 할당
- 프로세스들이 필요로 하는 각 자원별 최대 사용량을 미리 선언하도록 하는 방법
- 항상 safe state를 유지
2가지 경우의 avoidance 알고리즘
- 자원당 인스턴스가 하나인 경우: Resource Allocation Graph algorithm 사용
- 자원당 인스턴스가 여러 개인 경우: Banker’s algorithm 사용
Resource Allocation Graph algorithm
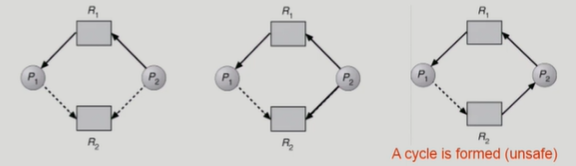
- 점선 화살표: 프로세스로부터 자원으로 가는 화살표만 있음. 프로세스가 적어도 한 번은 이 자원을 요청할 수 있다는 의미
- 현재 그림은 deadlock이 아님. 하지만 P1이 R2에게 자원을 요청할 경우 deadlock이 발생
- 최악을 가정하는 알고리즘이기 때문에 deadlock이 발생할 확률이 있는 경우(점선 화살표까지 포함해서 사이클이 완성될 경우) 자원을 할당하지 않음
Banker’s algorithm
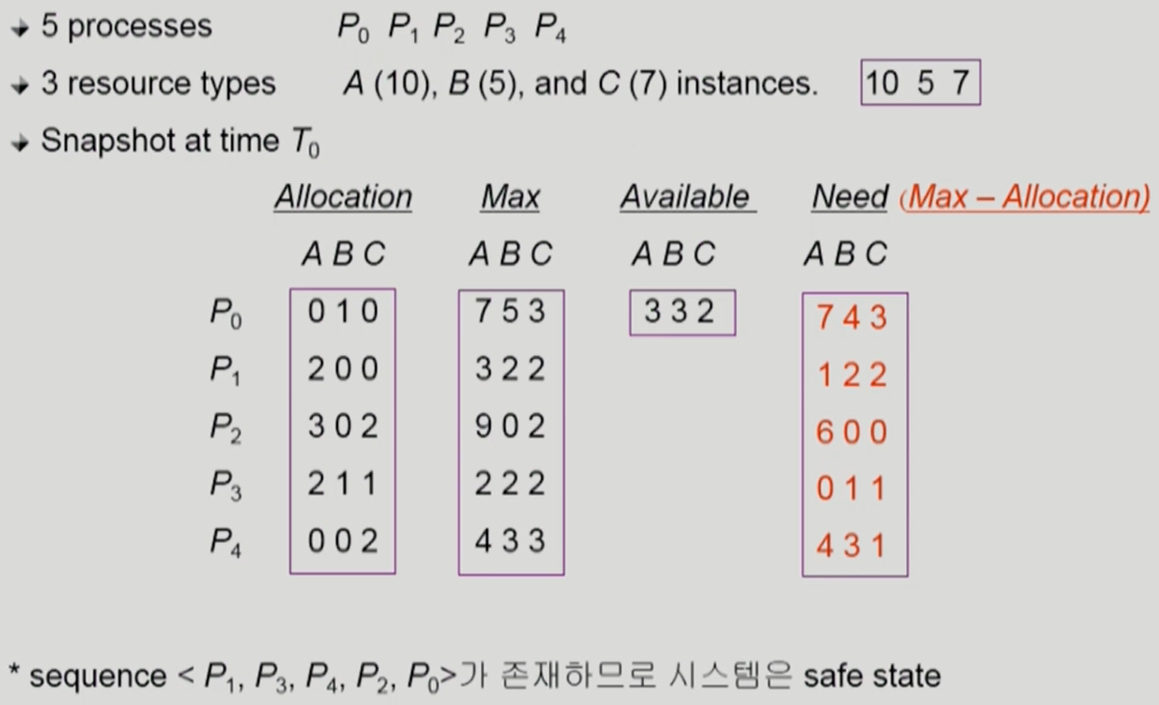
- Allocation: 할당된 자원의 개수 / Max: 최대로 자원을 사용할 때의 자원 개수 / Available: 현재 사용 가능한 자원의 개수
- Need: 추가로 할당 가능한 자원의 개수 (Max - Allocation)
- Banker’s algorithm은 항상 최대 요청을 할 것이라고 가정하고, 최대 요청이 현재 가용 자원을 가지고 충족이 되는지를 확인
- 충족이 될 경우, 어떤 요청이든 받아들임
- 충족이 되지 않을 경우, 요청을 받아들이지 않음
- Banker’s algorithm은 프로세스가 자원 요청을 했을 때 받아들일지 받아들이지 않을지를 결정하는 역할을 함
- sequence <P1, P3, P4, P2, P0>가 존재하므로 시스템은 safe state
- 각 프로세스의 최대 요청 자원을 모두 충족할 수 있는 sequence가 존재하면 이 상황은 safe한 상태로 절대 deadlock이 발생하지 않음
- 자원이 남아있어도 최악의 상황 때문에 자원을 할당하지 않으므로 비효율적
3. Deadlock Detection and recovery
Wait-for graph
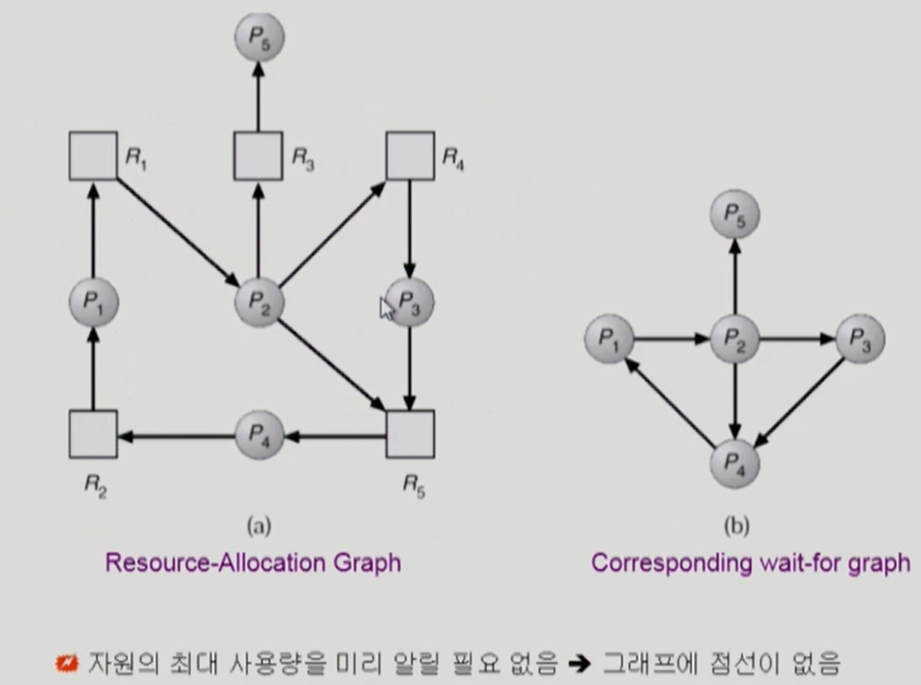
- 자원당 인스턴스가 하나인 경우 사용. 자원 할당 그래프를 변형시킨 그래프
- 프로세스만으로 node를 구성
- P_i가 가지고 있는 자원을 P_k가 기다리는 경우 P_k -> P_i
- wait-for graph에 사이클이 있는지를 주기적으로 조사 (O(n^2))
자원당 인스턴스가 여러 개인 경우

- Request: 추가 요청 가능량이 아닌 현재 실제로 요청한 자원량을 나타냄
- 만약 예시에서 P2가 C를 요청한다면 Deadlock 발생
- 가용 자원이 몇 개 있는지를 확인 후, 가용 자원으로 처리 가능한 프로세스가 있는지 확인. 자원을 요청하지 않은 프로세스에게 할당되어 있는 자원을 가용 자원으로 합쳐 놓고, 합친 가용 자원으로 처리 가능한 프로세스가 있는지 확인해 나감
Recovery
- Rrocess termination
- deadlock과 관련된 모든 프로세스 사살
- deadlock이 없어질 때까지 deadlock에 연류된 프로세스를 하나씩 죽임
- Resource Preemption
- deadlock에 연류된 프로세스에게서 자원을 뺏음
- 비용을 최소화할 희생양 선정 후 그 프로세스로부터 자원을 뺏어 deadlock을 없앤 후, safe state로 rollback해 process를 restart
- deadlock을 없앴지만, 같은 패턴으로 다시 문제 발생 가능 (Starvation 문제 발생 가능)
- 동일한 프로세스가 계속해서 희생양으로 선정되는 경우
- cost factor에 rollback 횟수도 같이 고려
4. Deadlock Ignorance
- Deadlock을 시스템이 책임지지 않음
- 만약, 시스템에 deadlock이 발생한 경우 시스템이 비정상적으로 작동하는 것을 사람이 느낀 후 직접 process를 죽이는 등의 방법으로 대처
현재는 4번 방법 채택!
deadlock은 빈번하게 발생하는 event가 아니고, deadlock에 대한 조치 자체가 더 큰 오버헤드일 수 있기 때문에 비효율적이라 생각. 따라서 deadlock이 발생하면 사용자가 deadlock을 처리하는 방법을 채택함
Chapter 7 끝!!!
게시물에 사용한 사진은 강의 내용을 캡쳐한 것입니다.
26 Jan 2022
|
TIL
학습과정
1. CS (운영체제)
Deadlock, Memory Management 부분 강의를 수강했다.
오늘 배운 내용
- Deadlock
- 데드락 발생 조건 4가지 + Resource-allocation graph
- 데드락 처리 방법: deadlock prevention, deadlock avoidance(banker’s algorithm), deadlock detection and recovery(wait-for graph), deadlock ignorance
- Memory management
- address binding: compile time binding, load time binding, execution time binding, MMU
- Dynamic Loading, Overlays, Swapping, Dynamic Linking
- Contiguous allocation: Fixed partition allocation, Variable partition allocation, Dynamic Storage-Allocation Problem, Compaction
2
이상하리만큼 공부에 집중이 되지 않는 날이었다.. 
공부하기 싫어 채용공고를 보고 있는데 한국 소프트웨어 산업협회에서 현대 IT&E 채용확정형 SW개발자 양성과정을 진행한다는 공고를 봤다. 커리큘럼을 살펴보니 나쁘지 않기도 하고, 채용전환률도 높다고 해서 교육 과정을 신청하고 1차로 지원서를 작성했다. 우선 내일까지 빠르게 1차 지원서 작성을 마무리하고 틈나는데로 수정해서 이번 주 내로 제출해야겠다.
내일은 진짜 멘탈 잡고 집중해서 공부해야겠다.. 
(화요일, 수요일 공부를 많이 못했더니 진도가 살짝 밀렸…  )
)
25 Jan 2022
|
자바의 정석
JAVA
1. 컬렉션 프레임웍의 핵심 인터페이스
- 컬렉션 프레임웍(Collections Framework): 데이터 군을 저장하는 클래스들을 표준화한 설계
- 컬렉션은 다수의 데이터, 즉 데이터 그룹을, 프레임웍은 표준화된 프로그래밍 방식을 의미
- 컬렉션 프레임웍은 컬렉션(다수의 데이터)을 다루는데 필요한 다양하고 풍부한 클래스들을 제공
- 인터페이스와 다형성을 이용한 객체지향적 설계를 통해 표준화되어 있기 때문에 사용법을 익히기에도 편리하고 재사용성이 높은 코드를 작성할 수 있음
- 컬렉션데이터 그룹을 3가지 타입(List, Set, Map)이 존재한다고 인식하고 각 컬렉션을 다루는데 필요한 기능을 가진 3개의 인터페이스를 정의
- 인터페이스 List와 Set의 공통된 부분을 다시 뽑아 새로운 인터페이스인 Collection을 추가로 정의
| 인터페이스 |
특징 |
| List |
- 순서가 있는 데이터의 집합. 데이터 중복을 허용
- 구현 클래스: ArrayList, LinkedList, Stack, Vector 등 |
| Set |
- 순서를 유지하지 않는 데이터의 집합. 데이터의 중복을 허용하지 않음
- 구현 클래스: HashSet, TreeSet 등 |
| Map |
- 키와 값의 쌍으로 이루어진 데이터의 집합. 순서는 유지되지 않으며, 키는 중복을 허용하지 않고, 값은 중복을 허용
- 구현 클래스: HashMap, TreeMap, Hashtable, Properties 등 |
- Vector, Stack, HashTable, Proerties와 같은 클래스들은 컬렉션 프레임웍이 만들어지기 이전부터 존재
- Vector, Hashtable과 같은 기존 컬렉션의 클래스들은 호환을 위해 설계를 변경해 남겨두었지만 가능하면 사용하지 않는 것이 좋음
- ArrayList, HashMap을 사용
Collection 인터페이스
List 인터페이스
Set 인터페이스
Map 인터페이스
-
Map 인터페이스에 정의된 메서드
- 키(key)와 값(value)을 하나의 쌍으로 묶어서 저장하는 컬렉션 클래스를 구현하는 데 사용됨
- 키가 중복될 수 없지만 값은 중복을 허용
- 기존에 저장된 데이터와 중복된 키와 값을 저장하면 기존의 값은 없어지고 마지막에 저장된 값이 남게 됨
-
values()에서는 반환타입이 Collection이고, keySet()에서는 반환타입이 Set
- Map 인터페이스에서 값은 중복을 허용하기 때문에 Collection 타입으로 반환하고, 키는 중복을 허용하지 않기 때문에 Set 타입으로 반환
Map.Entry 인터페이스
-
Map.Entry 인터페이스의 메서드
- Map 인터페이스의 내부 인터페이스
- 내부 클래스와 같이 인터페이스도 인터페이스 안에 인터페이스를 정의하는 내부 인터페이스를 정의하는 것이 가능
- Map에 저장되는 key-value 쌍을 다루기 위해 내부적으로 Entry 인터페이스를 정의해놓음
- Map 인터페이스를 구현하는 클래스에서는 Map.Entry 인터페이스도 함께 구현해야 함
2. ArrayList 클래스와 LinkedList 클래스
ArrayList
-
ArrayList의 생성자와 메서드
-
컬렉션 프레임웍에서 가장 많이 사용되는 컬렉션 클래스
-
List 인터페이스를 구현하기 때문에 데이터의 저장순서가 유지되고 중복을 허용함
-
Object 배열을 이용해 데이터를 순차적으로 저장
- 더 이상 저장할 공간이 없으면 더 큰 배열을 생성해 기존의 배열에 저장된 내용을 새로운 배열로 복사한 다음 저장하게 됨
-
elementData라는 이름의 Object 배열을 멤버변수로 선언
- 배열의 타입이 Object로 선언되었기 때문에 모든 종류의 객체를 담을 수 있음
-
ex) list2에서 list1과 공통되는 요소들을 찾아 삭제하는 코드
for (int i = list2.size()-1; i >= 0; i--){
if (list1.contains(list2.get(i)))
list2.remove(i)
}
- for문의 변수 i를 0부터 증가시키지 않고
list2.size()-1 부터 감소시킨 이유
- i를 증가시켜가면서 삭제하면, 한 요소가 삭제될 때마다 빈 공간을 채우기 위해 나머지 요소들이 자리이동을 하기 때문에 올바른 결과를 얻을 수 없기 때문
- 제어변수를 감소시켜가면서 삭제해야 자리이동이 발생해도 영향을 받지 않고 작업이 가능
-
ArrayList나 Vector 같이 배열을 이용한 자료구조는 데이터를 읽어오고 저장하는데 효율이 좋지만, 용량을 변경해야할 때는 새로운 배열을 생성한 후 기존의 배열로부터 새로 생성된 배열로 데이터를 복사해야하기 때문에 효율이 떨어진다는 단점이 있음
- 처음 인스턴스를 생성할 때, 저장할 데이터의 개수를 고려해 충분한 용량의 인스턴스를 생성하는 것이 좋음
LinkedList
배열의 장점과 단점
- 장점: 구조가 간단하며 사용하기 쉽고 데이터를 읽어오는데 걸리는 시간이 가장 빠름
- 단점
-
크기 변경이 불가
- 크기를 변경할 수 없으므로 새로운 배열을 생성해 데이터를 복사해야 함
- 실행속도를 향상시키기 위해서는 충분히 큰 크기의 배열을 생성해야 하므로 메모리가 낭비됨
-
비순차적인 데이터의 추가 또는 삭제에 시간이 오래 걸림
- 차례대로 데이터를 추가하고 마지막에서부터 데이터를 삭제하는 것은 빠름
- 배열의 중간에 데이터를 추가하려면, 빈자리를 만들기 위해 다른 데이터들을 복사해서 이동해야 함
- LinkedList는 불연속적으로 존재하는 데이터를 서로 연결한 형태로 구성되어 있음
class Node {
Node next; // 다음 요소의 주소를 저장
Object obj; // 데이터를 저장
}
- 링크드 리스트의 각 요소(node)들은 자신과 연결된 다음 요소에 대한 참조(주소값)와 데이터로 구성되어 있음
링크드 리스트에서의 데이터 삭제
- 삭제하고자 하는 요소의 이전요소가 삭제하고자 하는 요소의 다음 요소를 참조하도록 변경하면 됨
- 데이터를 이동하기 위해 복사하는 과정이 없기 때문에 처리 속도가 매우 빠름
링크드 리스트에서의 데이터 추가
- 새로운 요소를 생성한 다음 추가하고자 하는 위치의 이전 요소의 참조를 새로운 요소에 대한 참조로 변경해주고, 새로운 요소가 그 다음 요소를 참조하도록 변경
LinkedList 클래스
ArrayList와 LinkedList 비교
- 순차적으로 추가/삭제하는 경우에는 ArrayList가 LinkedList보다 빠름
- 단, ArrayList의 크기가 충분하지 않으면, 새로운 크기의 ArrayList를 생성하고 데이터를 복사하는 일이 발생하게 되므로 순차적으로 데이터를 추가해도 LinkedList가 더 빠를 수 있음
- 중간 데이터를 추가/삭제하는 경우에는 LinkedLiast가 ArrayList보다 빠름
- LinkedList는 각 요소간의 연결만 변경해주면 되기 때문에 처리속도가 빠르지만, ArrayList는 각 요소들을 재배치하여 추가할 공간을 확보하거나 빈 공간을 채워야하기 때문에 처리 속도가 느림
- 데이터를 읽어오는데 걸리는 시간(접근 시간)은 ArrayList가 LinkedList보다 빠름
3. Stack 인터페이스와 Queue 인터페이스
-
Stack의 메서드와 Queue의 메서드
- 스택은 마지막에 저장한 데이터를 가장 먼저 꺼내게 되는 LIFO 구조로 되어 있고, 큐는 처음에 저장한 데이터를 가장 먼저 꺼내게 되는 FIFO 구조로 되어 있음
- 순차적으로 데이터를 추가하고 삭제하는 스택에는 ArrayList와 같은 배열 기반의 컬렉션 클래스가 적합
- 큐는 데이터를 꺼낼 때 항상 첫 번째 저장된 데이터를 삭제하므로 LinkedList로 구현하는 것이 더 적합
- ArrayList와 같은 배열 기반 컬렉션 클래스로 구현할 경우 데이터를 꺼낼 때마다 빈 공간을 채우기 위해 데이터의 복사가 발생하므로 비효율적
- Queue의 인테페이스는 LinkedList에서 구현
스택과 큐의 활용
- 스택의 활용 예 - 수식계산, 수식괄호검사, 워드프로세서의 undo/redo, 웹브라우저의 뒤로/앞으로
- 큐의 활용 예 - 최근사용문서, 인쇄작업 대기목록, 버퍼(buffer)
PriorityQueue
- 저장한 순서에 관계없이 우선순위(priority)가 높은 것부터 꺼내게 됨
- 숫자의 경우, 숫자가 작을수록 높은 우선순위를 가짐
- 객체도 저장 가능하지만 각 객체의 크기를 비교할 수 있는 방법을 제공해야 함
- null 값 저장 불가. null를 저장하면 NullPointerException이 발생함
- PriorityQueue는 저장공간으로 배열을 사용하며, 각 요소를 ‘힙(heap)’이라는 자료구조의 형태로 저장함
- 힙(heap): 이진 트리의 한 종류로 가장 큰 값이나 가장 작은 값을 빠르게 찾을 수 있음
Deque(Double-Ended Queue)
4. Iterator, ListIterator, Enumeration
- 컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스
- Enumeration은 Iterator의 구버전이며, ListIterator는 Iterator의 기능을 향상시킨 것
Iterator
-
Iterator 인터페이스의 메서드
- 컬렉션 프레임웍에서는 컬렉션에 저장된 요소들을 읽어오는 방법을 표준화함
- 컬렉션에 저장된 각 요소에 접근하는 기능을 가진 Iterator 인터페이스를 정의하고, Collection 인터페이스에는 ‘Iterator(Iterator를 구현한 클래스의 인스턴스)’를 반환하는
iterator()를 정의
-
iterator()는 Collection 인터페이스에 정의된 메서드이므로 Collection 인터페이스의 자손인 List와 Set도 포함되어 있음
- List나 Set 인터페이스를 구현하는 컬렉션은
iterator()가 각 컬렉션의 특징에 맞게 작성되어 있음
- 컬렉션 클래스에 대해
iterator()를 호출하여 Iterator를 얻은 다음 반복문(주로 while문)을 사용해서 컬렉션 클래스의 요소들을 읽어올 수 있음
- Map 인터페이스를 구현한 컬렉션 클래스는 키와 값을 쌍으로 저장하고 있기 때문에
iteratior()를 직접 호출할 수 없고, 그 대신 keySet()이나 entrySet()과 같은 메서드를 통해 키와 값을 각각 따로 Set의 형태로 얻어 온 후 다시 iterator()를 호출해야 Iterator를 얻을 수 있음
ListIterator와 Enumeration
- Enumeration: 컬렉션 프레임웍이 만들어지기 이전에 사용하던 것으로 Iterator의 구버전
- ListIterator: Iterator를 상속받아 기능을 추가한 것
- ListIterator의 메서드
- 컬렉션의 요소에 접근할 때 Iterator는 단방향으로만 이동할 수 있는 반면, ListIterator는 양방향으로 이동 가능
- ArrayList나 LinkedList와 같이 List 인터페이스를 구현한 컬렉션에서만 사용 가능
5. Arrays
배열의 복사 - copyOf(), copyOfRange()
-
copyOf()는 배열 전체를, copyOfRange()는 배열의 일부를 복사해 새로운 배열을 만들어 반환
배열 채우기 - fill(), setAll()
-
fill()은 배열의 모든 요소를 지정된 값으로 채우고, setAll()은 배열을 채우는데 사용할 함수형 인터페이스를 매개변수로 받음
-
setAll() 를 호출할 때는 함수형 인터페이스를 구현한 객체를 매개변수로 지정하던가 아니면 람다식을 지정해야함
배열의 정렬과 검색 - sort(), binarySearch()
-
sort()는 배열을 정렬할 때, binarySearch()는 배열에 저장된 요소를 검색할 때 사용
-
binarySearch()는 배열에서 지정된 값이 저장된 위치(index)를 찾아서 반환하는데, 반드시 배열이 정렬된 상태여야 올바른 결과를 얻음
- 검색한 값과 일치하는 요소들이 여러 개 있다면, 이 중 어떤 것의 위치가 반환될지는 알 수 없음
배열의 비교와 출력 - equals(), toString()
-
toString()은 배열의 모든 요소를 문자열로 출력
- 일차원 배열에만 사용할 수 있으므로, 다차원 배열에는
deepToSting()를 사용해야 함
-
equals()는 두 배열에 저장된 모든 요소를 비교해서 같으면 true, 다르면 false를 반환
- 일차원 배열만 사용 가능하므로, 다차원 배열에서는
deepEquals()를 사용해야 함
- 다차원 배열에서
equals()로 값을 비교하게 되면 문자열을 비교하는 것이 아니라 배열에 저장된 배열의 주소를 비교하게 되기 때문에 항상 false를 결과로 얻음
배열을 List로 변환 - asList(Object… a)
-
asList()는 배열을 List에 담아서 반환
- 매개변수의 타입이 가변인수라 배열 생성 없이 저장할 요소들만 나열하는 것도 가능
-
asList()가 반환한 List의 크기는 변경 불가. 추가 또는 삭제가 불가능하지만 저장된 내용은 변경 가능
parallelXXX(), spliterator(), stream()
- 빠른 결과를 얻기 위해 여러 쓰레드가 작업을 나눠어 처리
-
spliterator()는 여러 쓰레드가 처리할 수 있게 하나의 작업을 여러 작업으로 나누는 Spliterator를 반환하며, stream()은 컬렉션을 스트림으로 변환함
6. Comparator와 Comparable
- Comparator와 Comparable은 모두 인터페이스로 컬렉션을 정렬하는데 필요한 메서드를 정의
- Comparable을 구현하고 있는 클래스들은 같은 타입의 인스턴스끼리 서로 비교할 수 있는 클래스들이며 기본적으로 오름차순으로 정렬되도록 구현되어 있음
- Comparable를 구현한 클래스 목록
- 주로 Integer와 같은 wrapper 클래스와 String, Date, File과 같은 클래스들을 비교
- Comparable을 구현한 클래스는 정렬이 가능하다는 것을 의미
- Comparable을 구현한 클래스들이 기본적으로 오름차순으로 정렬되어 있지만, 내림차순으로 정렬한다던가 아니면 다른 기준에 의해 정렬되도록 하고 싶을 때 Comparator를 구현해서 정렬기준을 제공할 수 있음
Comparable 기본 정렬기준을 구현하는데 사용
Comparator 기본 정렬기준 외에 다른 기준으로 정렬하고자할 때 사용