28 Jan 2022
|
알고리즘
프로그래밍
자바
silver 4. 보물 (1026)
출처 : https://www.acmicpc.net/problem/1026
문제
길이가 N인 정수 배열 A와 B가 있을 때, 함수 S를 아래와 같이 정의할 때 S의 최솟값을 출력하는 프로그램 작성
[S = A[0] X B[0] + … + A[N-1] X B[N-1]]
- S의 값을 가장 작게 만들기 위해 A의 수를 재배열. 단, B에 있는 수는 재배열하면 안됨
입력: 첫째 줄에 N이 주어지고, 둘째 줄에는 A에 있는 N개의 수가 순서대로 주어지고, 셋째 줄에는 B에 있는 수가 순서대로 주어짐
- N은 50보다 작거나 같은 자연수이고, A와 B의 각 원소는 100보다 작거나 같은 음이 아닌 정수
출력: S의 최솟값 출력
풀이
- 아이디어: A, B를 오름차순으로 정렬한 후 A의 가장 작은 수는 B의 가장 큰 수와 곱해주는 방식으로 해결
import java.util.*;
public class Main {
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
int N = sc.nextInt(); // 배열 크기 저장
int[] A = new int[N];
int[] B = new int[N];
int result = 0; // S의 최솟값 저장
String space = sc.nextLine(); // N의 값을 입력받고 문자를 입력받기 전 기존의 enter 값을 없애주는 변수
StringTokenizer st = new StringTokenizer(sc.nextLine()); // A의 값을 받아옴
for(int i=0; i < N; i++){
A[i] = Integer.parseInt(st.nextToken()); // 받아온 값을 int형으로 변환 후 A에 값을 저장
}
StringTokenizer st2 = new StringTokenizer(sc.nextLine()); // B의 값을 받아옴
for(int i=0; i < N; i++){
B[i] = Integer.parseInt(st2.nextToken()); // 받아온 값을 int형으로 변환 후 B에 값을 저장
}
Arrays.sort(A); // A를 오름차순으로 정렬
Arrays.sort(B); // B를 오름차순으로 정렬
for (int i = 0; i < N; i++){
result += A[i] * B[N-1-i]; // S의 최솟값을 구함
}
System.out.println(result);
}
}
- 백준에 제출했을 때 코드는 통과했지만, 문제에서 B에 있는 수는 재배열하면 안 된다는 조건을 만족시키지 못했다.
- B에 있는 수를 재배열하지 않으면서 S의 최솟값을 찾을 수 있는 방법을 다시 생각해봐야겠다.
배운점
-
nextInt() 메서드 다음 nextLine() 메서드를 실행하면, nextLine() 메서드가 그냥 넘어가버리는 오류가 발생
- 이유:
nextInt() 메서드를 실행할 때 숫자를 입력하고 엔터를 누르면 숫자는 리턴시키지만 엔터의 값은 그대로 남아있음. nextLine() 메서드는 enter 값을 기준으로 메서드를 종료시키기 때문에 nextLine() 메서드가 실행될 때 남아있는 enter 값을 그대로 읽어 바로 종료됨
-
해결 방법: 정수를 입력하고 그 다음 문자를 입력하고자 할 때는 next() 메서드를 사용하거나, 문자를 입력받기 전 nextLine() 메서드를 한번 더 써줘서 기존은 enter 값을 없애주어야 함
추가
-
2022-02-03 추가
- 처음 풀었을 때는 B에 있는 수를 재배열하지 말라는 조건을 충족시키지 못했다. 조건을 충족시켜 푼 풀이를 추가한다.
- 아이디어
- B에서 최댓값을 찾아주는 max 메서드를 생성함
- A 메서드는
Arrays.sort()를 이용해 오름차순으로 정렬해줌
- for문을 돌면서 B의 최댓값을 찾아주는 함수를 호출해 B의 최댓값과 A의 최솟값을 곱한 후 result 값에 더해줌
import java.util.*;
public class Main{
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
int N = sc.nextInt();
int[] A = new int[N];
int[] B = new int[N];
int result = 0;
String space = sc.nextLine();
StringTokenizer st1 = new StringTokenizer(sc.nextLine());
for(int i=0; i < N; i++){
A[i] = Integer.parseInt(st1.nextToken());
}
StringTokenizer st2 = new StringTokenizer(sc.nextLine());
for (int i=0; i < N; i++){
B[i] = Integer.parseInt(st2.nextToken());
}
// A를 오름차순으로 정렬
Arrays.sort(A);
// B와 같은 값을 가지는 BCopy 생성
int[] BCopy = Arrays.copyOf(B, N);
for(int i=0; i < N; i++) {
int B_max = max(BCopy); // B에서의 최댓값을 찾아줌
result += A[i] * B_max; // A의 최솟값과 B의 최댓값을 곱한 후 result에 더해줌
}
System.out.println(result);
}
// B에서의 최댓값을 찾아주는 함수
public static int max(int[] arr){
int index = -1; // 최댓값의 인덱스 값을 저장
int max = -1; // 최댓값 저장
// for문을 통해 최댓값을 찾아줌
for(int i=0; i < arr.length; i++){
if (max < arr[i]){
max = arr[i];
index = i;
}
}
// 최댓값 다음으로 큰 값을 찾기 위해 최댓값을 가진 인덱스에 해당하는 값을 0으로 변경
arr[index] = 0;
// 최댓값 return
return max;
}
}
-
2022-02-04 추가
- 스터디 진행하며 코드 리뷰를 하던 중, A의 최솟값과 B의 최댓값을 곱해나가는 과정이 아니라 A의 최댓값과 B의 최솟값을 곱해나가는 과정으로 계산을 하면 통과할까? 라는 질문이 나와 코드를 약간 수정해 테스트해봄
- 위의 로직으로도 테스트 통과함
import java.util.*;
public class Main{
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
int N = sc.nextInt();
int[] A = new int[N];
int[] B = new int[N];
int resultMin = 0;
String space = sc.nextLine();
StringTokenizer st1 = new StringTokenizer(sc.nextLine());
for(int i=0; i < N; i++){
A[i] = Integer.parseInt(st1.nextToken());
}
StringTokenizer st2 = new StringTokenizer(sc.nextLine());
for (int i=0; i < N; i++){
B[i] = Integer.parseInt(st2.nextToken());
}
Arrays.sort(A);
int[] BCopy = Arrays.copyOf(B, N);
for(int i=0; i < N; i++) {
int B_min = min(BCopy); // B의 최솟값을 찾아주는 함수 호출
resultMin += A[N-1-i] * B_min; // A의 최댓값과 B의 최솟값을 곱해줌
}
System.out.println(resultMin);
}
// B의 최댓값을 구해주는 함수 대신 B의 최솟값을 구해주는 함수로 수정
public static int min(int[] arr){
int index = 0;
int min = 101;
for(int i=0; i < arr.length; i++){
if (min > arr[i]){
min = arr[i];
index = i;
}
}
arr[index] = 101;
return min;
}
}
28 Jan 2022
|
TIL
학습과정
1. 자바의 정석
지네릭스, 열거형, 애너테이션 부분을 공부했다.
- 지네릭스(Generics)
- 와일드 카드
- 지네릭 메서드
- 지네릭 타입 형변환
- 열거형(enums)
- 열거형에 멤버 추가하기
- 열거형에 추상 메서드 추가하기
- 애너테이션(annotation)
- 표준 애너테이션
- 메타 애너테이션
- 애너테이션 타입 정의하기 (애너테이션 요소의 규칙)
2. 알고리즘
silver 4. 보물(1026) 문제를 풀었다.
- 아이디어는 빨리 떠올랐지만, 문제 조건 하나를 만족시키지 못했고, 구현에서도 조금 오래 걸렸다.
- 구현에서 오래 걸린 이유는 Scanner을 통해 값을 입력받을 때
nextInt()를 사용하고 바로 nextLine()를 통해 값을 입력받으려 했지만, nextLine()을 통해 값을 입력받으려할 때 프로그램이 종료되었다. 이 부분을 해결하는데 조금 오래 걸렸다. => 이 부분은 문제 해설 링크 참조
3
현대 IT&E 채용 확정형 교육 지원서를 마무리하고 제출했다. 그냥 가볍게 넣어본 서류지만 그래도 합격했으면 좋겠다,,
27 Jan 2022
|
자바의 정석
JAVA
1. HashSet
- HashSet의 메서드
- Set 인터페이스를 구현한 가장 대표적인 컬렉션
- HashSet은 중복된 요소를 저장하지 않음
- HashSet에 이미 저장되어 있는 요소와 중복된 요소를 추가하고자 한다면 add 메서드나 addAll 메서드는 false를 반환
- 이 특징을 이용하면, 컬렉션 내의 중복 요소들을 쉽게 제거 가능
- HashSet은 저장순서를 유지하지 않으므로 저장순서를 유지하고자 한다면 LinkedHashSet을 사용해야 함
2. TreeSet
- TreeSet의 생성자와 메서드
- 이진 검색 트리(binary search tree)라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스
- 이진 검색트리는 정렬, 검색, 범위검색(range search)에 높은 성능을 보이는 자료구조
- TreeSet은 이진 검색 트리의 성능을 향상시킨 Red-Black tree로 구현됨
- Set 인터페이스를 구현했으므로 중복된 데이터의 저장을 허용하지 않으며 정렬된 위치에 저장하므로 저장순서를 유지하지도 않음
이진 트리(binary tree)
- 여러 개의 노드(node)가 서로 연결된 구조
- 각 노드에 최대 2개의 노드를 연결할 수 있으며 root라고 불리는 하나의 노드에서부터 시작해 계속 확장해 나감
- 위 아래로 연결된 두 노드를 ‘부모-자식관계’에 있다고 함. 하나의 부모 노드는 최대 두 개의 자식 노드와 연결될 수 있음
class TreeNode {
TreeNode left; // 왼쪽 자식노드
Object element; // 객체를 저장하기 위한 참조변수
TreeNode right; // 오른쪽 자식노드
}
- 데이터를 저장하기 위한 Object 타입의 참조변수 하나와 두 개의 노드를 참조하기 위한 두 개의 참조변수를 선언
이진 검색 트리(binary search tree)
- 부모노드의 왼쪽에는 부모노드의 값보다 작은 값의 자식노드를 오른쪽에는 큰 값의 자식노드를 저장하는 이진 트리
- 첫 번째로 저장되는 값은 루트가 되고, 두 번째 값은 트리의 루트부터 시작해 값의 크기를 비교하면서 트리를 따라 내려감
- 작은 값은 왼쪽에 큰 값은 오른쪽에 저장
- 왼쪽 마지막 레벨이 제일 박은 값이 되고 오른쪽 마지막 레벨의 값이 제일 큰 값이 됨
-
TreeSet에 저장되는 객체가 Comparable을 구현하던가 아니면, TreeSet에게 Comparator를 제공해서 두 객체를 비교할 방법을 알려줘야 함. 그렇지 않으면, TreeSet에 객체를 저장할 때 예외 발생
-
왼쪽 마지막 값에서부터 오른쪽 값까지 값을 왼쪽 노드 -> 부모 노드 -> 오른쪽 노드 순으로 읽오면 오참차순으로 정렬된 순서를 얻을 수 있음
- TreeSet은 정렬된 상태를 유지하기 때문에 단일 값 검색과 범위검색이 매우 빠름
- 트리는 데이터를 순차적으로 저장하는 것이 아니라 저장위치를 찾아서 저장해야하고, 삭제하는 경우 트리의 일부를 재구성해야하므로 링크드 리스트보다 데이터의 추사/삭제 시간은 더 걸림
- 배열이나 링크드 리스트에 비해 검색과 정렬 기능이 더 뛰어남
3. HashMap과 Hashtable
- HashMap의 생성자와 메서드
- Hashtable보다는 새로운 버전인 HashMap을 사용하는 것이 좋음
- HashMap은 Map을 구현했으므로, 키(key)와 값(value)을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어 성능이 뛰어남
Entry[] table;
class Entry{
Object key;
Object value;
}
해싱과 해시함수
- 해싱: 해시함수(hash function)를 이용해서 데이터를 해시테이블(hash table)에 저장하고 검색하는 기법
- 해시함수는 데이터가 저장되어 있는 곳을 알려 주기 때문에 다량의 데이터 중에서도 원하는 데이터를 빠르게 찾을 수 있음
- 해싱을 구현한 컬렉션 클래스로는
HashSet, HashMap, HashTable 등이 있음
HashTable은 컬렉션 프레임웍이 도입되면서 HashMap으로 대체되었으나 호환성 문제로 남겨둠
- 해싱에 사용하는 자료구조는 배열과 링크드 리스트의 조합으로 되어 있음
- 저장할 데이터의 키를 해시함수에 넣으면 배열의 한 요소를 얻게 되고, 다시 그 곳에 연결되어 있는 링크드 리스트에 저장하게 됨
HashMap에 저장된 데이터를 찾는 과정
- 검색하고자 하는 값의 키로 해시함수를 호출함
- 해시함수의 계산결과(해시코드)로 해당 값이 저장되어 있는 링크드 리스트를 찾음
- 링크드 리스트에서 검색한 키와 일치하는 데이터를 찾음
-
하나의 서랍에 많은 데이터가 저장되어 있는 형태보다 많은 서랍에 하나의 데이터만 저장되어 있는 형태가 더 빠른 검색결과를 얻을 수 있음
- 하나의 링크드 리스트(서랍)에 최소한의 데이터만 저장하려면, 저장될 데이터의 크기를 고려해 HashMap의 크기를 적절하게 지정해주어야 함
- 해시함수가 서로 다른 키에 대해 중복된 해시코드의 반환을 최소화해야 함
-
해싱을 구현한 컬렉션 클래스에서는 Object 클래스에 정의된 hashCode()를 해시함수로 사용함
- Object 클래스에 정의된
hashCode()는 객체의 주소를 이용하는 알고리즘으로 해시코드를 만들어 냄
- String 클래스의 경우, Object로부터 상속받은
hashCod()를 오버라이딩해서 문자열의 내용으로 해시코드를 만들어 냄. 따라서 서로 다른 String인스턴스일지라도 같은 내용의 문자열을 가졌다면 hashCode()를 호출하면 같은 해시코드를 얻음
- HashSet은 서로 다른 두 객체에 대해
equals()로 비교한 결과가 true인 동시에 hashCode()의 반환값이 같아야 같은 객체로 인식
-
HashMap도 같은 방법을 사용해 객체를 구별하며, 이미 존재하는 키에 대한 값을 저장하면 기존의 값을 새로운 값으로 덮어씀
- 새로운 클래스를 정의할 때
equals()를 재정의 오버라이딩해야 한다면 hashCod()도 같이 재정의해서 equals()의 결과가 true인 두 객체의 해시코드 hashCode()의 결과 값이 항상 같도록 해주어야 함
- 그렇지 않으면 HashMap과 같이 해싱을 구현한 컬렉션 클래스에서는
equals()의 호출결과가 true이지만 해시코드가 다른 두 객체를 다른 것으로 인식하고 따로 저장할 것
equals()로 비교한 결과가 false이고 해시코드가 같은 경우는 같은 링크드 리스트에 저장된 서로 다른 두 데이터가 됨
4. TreeMap
- TreeMap의 생성자와 메서드
- 이진검색트리의 형태로 키와 값의 쌍으로 이주어진 데이터를 저장
- 검색과 정렬에 적합한 컬렉션 클래스
- HashMap과 TreeMap 중 검색에 관한한 대부분의 경우 HashMap이 TreeMap보다 더 뛰어나므로 HashMap을 사용하는 것이 좋고, 범위검색이나 정렬이 필요한 경우에는 TreeMap을 사용하는 것이 좋음
5. Properties
- Properties의 생성자와 메서드
- Hashtable을 상속받아 구현한 것
- Hashtable은 키와 값을 (Object, Object)의 형태로 저장하는데 비해 Properties는 (String, String) 형태로 저장하는 단순화된 컬렉션 클래스
- 애플리케이션의 환경설정과 관련된 속성을 저장하는데 사용되며 데이터를 파일로부터 읽고 쓰는 기능을 제공
- Properties는 Hashtable을 상속받아 구현한 것이므로 Map이 특성상 저장순서를 유지하지 않음
6. Collections
- 컬렉션과 관련된 메서드를 제공
java.util.Collection은 인터페이스, java.util.Collections는 클래스
컬렉션의 동기화
- 멀티 쓰레드 프로그래밍에서는 하나의 객체를 여러 쓰레드가 동시에 접근할 수 있기 때문에 데이터의 일관성(consistency)을 유지하기 위해서는 공유되는 객체에 동기화(synchronization)이 필요
- ArrayList, HashMap과 같은 컬렉션은 동기화를 자체적으로 처리하지 않고 필요한 경우에만
java.util.Collections 클래스의 동기화 메서드를 이용해 동기화 처리가 가능하도록 함
변경불가 컬렛션 만들기
- 컬렉션에 저장된 데이터를 보호하기 위해 컬렉션을 변경할 수 없게, 읽기전용으로 만들어야 할 때가 있음
- 멀티 쓰레드 프로그래밍에서 여러 쓰레드가 하나의 컬렉션을 공유하다보면 데이터가 손상될 수 있는데, 이를 방지하고자 할 때 사용
unmodifiable이 붙은 메서드 사용
싱클톤 컬렉션 만들기
한 종류의 객체만 저장하는 컬렉션 만들기
- 컬렉션에 지정된 종류의 객체만 저장할 수 있도록 제한하고 싶을 때 사용
-
checked가 붙은 메서드 사용
- 두 번째 매개변수에 저장할 객체의 클래스를 지정
컬렉션 클래스 정리
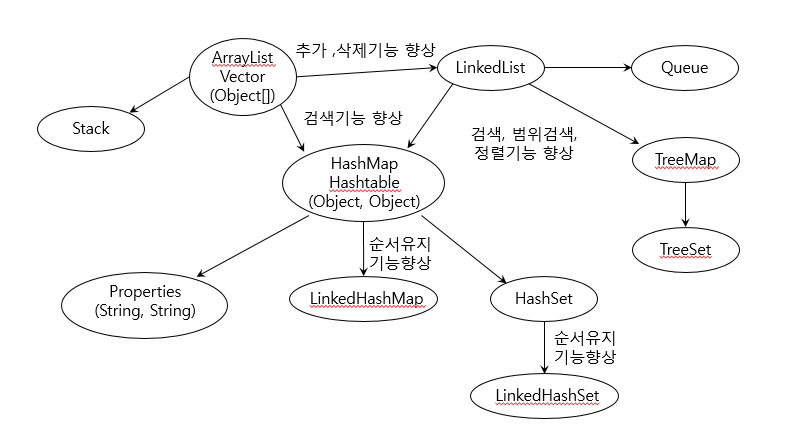
이미지 출처: https://steady-snail.tistory.com/78
| 컬렉션 |
특징 |
| ArrayList |
배열기반, 데이터의 추가와 삭제에 불리, 순차적인 추가삭제는 제일 빠름. 임의의 요소에 대한 접근성(accessibility)이 뛰어남 |
| LinkedList |
연결기반. 데이터의 추가와 삭제에 유리. 임의의 요소에 대한 접근성이 좋지 않음 |
| HashMap |
배열과 연결이 결합된 형태. 추가, 삭제, 검색, 접근성이 모두 뛰어남. 검색에는 최고 성능을 보임 |
| TreeMap |
연결기반. 정렬과 검색에 적합. 검색성능은 HashMap보다 떨어짐 |
| Stack |
Vector를 상속받아 구현 |
| Queue |
LinkedList가 Queue 인터페이스를 구현 |
| Properties |
Hashtable을 상속받아 구현 |
| HashSet |
HashMap을 이용해서 구현 |
| TreeSet |
TreeMap을 이용해서 구현 |
LinkedHashMap
LinkedHashSet |
HashMap과 HashSet에 저장순서 유지기능 추가 |
Chapter 11 끝!!!
27 Jan 2022
|
알고리즘
프로그래밍
자바
bronze 1. 설탕 배달 (2839)
출처 : https://www.acmicpc.net/problem/2839
문제
설탕을 정확하게 N 킬로그램을 배달해야 함. 봉지는 3 킬로그램, 5 킬로그램이 있음. 최대한 적은 봉지로 배달하려고 할 때 봉지 몇 개를 가져가면 되는지 그 수를 구하는 프로그램을 작성
입력: 배달해야할 설탕 무게
출력: 들고가야할 봉지 수
풀이
- 아이디어: 5 킬로그램 봉지를 최대한 많이 들고가는 것이 효율적
- 주어진 무게가 5의 배수일 경우 5로 나눈 몫만큼의 봉지만 들고가면됨
- 5의 배수가 아닐 경우 5의 배수가 될 때까지 무게에서 3을 빼준 후 봉지 수를 3를 빼준 횟수만큼 증가시킴
- 3을 뺀 후 남은 무게가 0보다 작을 경우
-1를 출력하고 프로그램을 종료 (정확하게 N 킬로그램을 만들 수 없는 경우)
import java.util.*;
public class Main {
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
int num = sc.nextInt();
int count = 0;
while(true) {
// 무게가 5의 배수인 경우
if (num % 5 == 0){
count += num / 5;
System.out.println(count);
break;
}
// 무게가 5의 배수가 아닌 경우
else {
num -= 3;
count ++;
}
// 정확하게 N 킬로그램을 만들 수 없는 경우
if (num < 0){
System.out.println(-1);
break;
}
}
}
}
27 Jan 2022
|
알고리즘
프로그래밍
자바
silver 5. 30 (10610)
출처 : https://www.acmicpc.net/problem/10610
문제
입력된 수에 포함된 숫자들을 섞어 30의 배수가 되는 가장 큰 수를 만들어주는 프로그램
입력: N를 입력받음. N은 최대 10^5개의 숫자로 구성되어 있으며, 0으로 시작하지 않음
출력: 주어진 숫자로 30의 배수를 만들 수 있다면, 만들 수 있는 30의 배수 중 가장 큰 수 출력. 만들 수 없다면, -1를 출력
풀이
- 아이디어: 30의 배수는 마지막 자리가 항상 0이고, 각 자리수의 합이 3의 배수가 되어야 함
- StringBuffer로 입력된 변수를 저장하고 for문을 통해 각 자리수를 더해줌
- 각 자리수의 합이 3의 배수인 경우, 주어진 수로 만들 수 있는 가장 큰 30의 배수를 찾기 위해 각 자리수를 정렬해주어야 함
- StringBuffer 변수의 경우 정렬해주는 함수가 없으므로 char형 배열로 변경해
sort()를 수행
sort()의 결과는 오름차순이므로, StringBuffer 변수로 값을 받아와 reverse() 연산을 수행함- 연산을 마치면 정수형으로 형 변환 해준 뒤 출력
- 각 자리수의 합이 3의 배수가 아닌 경우, 입력받은 수로 30의 배수를 만들어줄 수 없으므로
-1를 출력
1차 코드
import java.util.*;
public class Main {
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
StringBuffer tmp = new StringBuffer(sc.nextLine());
int result = 0;
// 각 자리 수를 모두 더해 result에 저장
for (int i=0; i<tmp.length(); i++){
result += tmp.charAt(i);
}
// result가 3의 배수인 경우 (입력받은 숫자로 30의 배수를 만들 수 있는 경우)
if (result % 3 == 0){
char[] cArr = tmp.toString().toCharArray(); // 정렬을 위해 char형 배열로 생성
Arrays.sort(cArr); // 오름차순으로 정렬
tmp = new StringBuffer(new String(cArr)).reverse(); // Stringbuffer에 저장 후 내림차순으로 변경
System.out.println(Integer.parseInt(tmp.toString())); // 정수형으로 형변환 후 결과를 보여줌
}
else{ // result가 3의 배수가 아닌 경우 (입력받은 숫자로 30의 배수를 만들 수 없는 경우)
System.out.println(-1);
}
}
}
2차 코드
import java.util.*;
public class Main {
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
StringBuffer tmp = new StringBuffer(sc.nextLine());
int result = 0;
for (int i=0; i<tmp.length(); i++){
result += tmp.charAt(i)-'0';
}
if (result % 3 == 0){
char[] cArr = tmp.toString().toCharArray();
Arrays.sort(cArr);
StringBuffer num = new StringBuffer(new String(cArr)).reverse();
System.out.println(num.toString()); // 수정
}
else{
System.out.println(-1);
}
}
}
- 출력할 때 int형으로 형변환해주지 않고 문자열로 출력해주는 코드로 변경
- 결과
- 백준에 제출했을 때 출력 초과 발생
- 원인: 30의 배수이기 위해서는 input 값에 0이 포함되어 있어야 하는데 input 값에서 0의 존재를 확인하는 조건을 빼먹음
3차 코드
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
StringBuilder num = new StringBuilder(sc.nextLine());
int sum = 0;
for (int i=0; i < num.length(); i++){
sum += num.charAt(i);
}
if (num.toString().contains("0") && (sum % 3 == 0)){ // 수정
char[] cArr = num.toString().toCharArray();
Arrays.sort(cArr);
num = new StringBuilder(new String(cArr)).reverse();
System.out.println(num.toString());
}
else {
System.out.println(-1);
}
}
}
- if문 조건에 input 값에서 0의 존재를 확인하는 코드 추가
- StringBuffer 대신 StringBuilder 사용
- 이유: StringBuffer는 멀티 쓰레드 환경에서 동기화 때문에 사용하는 것이기 때문에 알고리즘같은 단일 쓰레드 환경에서는 StringBuilder가 성능이 더 좋음
배운점
