
Chapter 11. 컬렉션 프레임웍_2
27 Jan 2022 | 자바의 정석 JAVA1. HashSet
- HashSet의 메서드
- Set 인터페이스를 구현한 가장 대표적인 컬렉션
- HashSet은 중복된 요소를 저장하지 않음
- HashSet에 이미 저장되어 있는 요소와 중복된 요소를 추가하고자 한다면 add 메서드나 addAll 메서드는 false를 반환
- 이 특징을 이용하면, 컬렉션 내의 중복 요소들을 쉽게 제거 가능
- HashSet은 저장순서를 유지하지 않으므로 저장순서를 유지하고자 한다면 LinkedHashSet을 사용해야 함
2. TreeSet
- TreeSet의 생성자와 메서드
- 이진 검색 트리(binary search tree)라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스
- 이진 검색트리는 정렬, 검색, 범위검색(range search)에 높은 성능을 보이는 자료구조
- TreeSet은 이진 검색 트리의 성능을 향상시킨 Red-Black tree로 구현됨
- Set 인터페이스를 구현했으므로 중복된 데이터의 저장을 허용하지 않으며 정렬된 위치에 저장하므로 저장순서를 유지하지도 않음
이진 트리(binary tree)
- 여러 개의 노드(node)가 서로 연결된 구조
- 각 노드에 최대 2개의 노드를 연결할 수 있으며 root라고 불리는 하나의 노드에서부터 시작해 계속 확장해 나감
- 위 아래로 연결된 두 노드를 ‘부모-자식관계’에 있다고 함. 하나의 부모 노드는 최대 두 개의 자식 노드와 연결될 수 있음
class TreeNode {
TreeNode left; // 왼쪽 자식노드
Object element; // 객체를 저장하기 위한 참조변수
TreeNode right; // 오른쪽 자식노드
}
- 데이터를 저장하기 위한 Object 타입의 참조변수 하나와 두 개의 노드를 참조하기 위한 두 개의 참조변수를 선언
이진 검색 트리(binary search tree)
- 부모노드의 왼쪽에는 부모노드의 값보다 작은 값의 자식노드를 오른쪽에는 큰 값의 자식노드를 저장하는 이진 트리
- 첫 번째로 저장되는 값은 루트가 되고, 두 번째 값은 트리의 루트부터 시작해 값의 크기를 비교하면서 트리를 따라 내려감
- 작은 값은 왼쪽에 큰 값은 오른쪽에 저장
- 왼쪽 마지막 레벨이 제일 박은 값이 되고 오른쪽 마지막 레벨의 값이 제일 큰 값이 됨
-
TreeSet에 저장되는 객체가 Comparable을 구현하던가 아니면, TreeSet에게 Comparator를 제공해서 두 객체를 비교할 방법을 알려줘야 함. 그렇지 않으면, TreeSet에 객체를 저장할 때 예외 발생
-
왼쪽 마지막 값에서부터 오른쪽 값까지 값을
왼쪽 노드 -> 부모 노드 -> 오른쪽 노드순으로 읽오면 오참차순으로 정렬된 순서를 얻을 수 있음 - TreeSet은 정렬된 상태를 유지하기 때문에 단일 값 검색과 범위검색이 매우 빠름
- 트리는 데이터를 순차적으로 저장하는 것이 아니라 저장위치를 찾아서 저장해야하고, 삭제하는 경우 트리의 일부를 재구성해야하므로 링크드 리스트보다 데이터의 추사/삭제 시간은 더 걸림
- 배열이나 링크드 리스트에 비해 검색과 정렬 기능이 더 뛰어남
3. HashMap과 Hashtable
- HashMap의 생성자와 메서드
- Hashtable보다는 새로운 버전인 HashMap을 사용하는 것이 좋음
- HashMap은 Map을 구현했으므로, 키(key)와 값(value)을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어 성능이 뛰어남
Entry[] table;
class Entry{
Object key;
Object value;
}
-
HashMap은 Entry라는 내부 클래스를 정의하고, 다시 Entry 타입의 배열을 선언
- 키와 값은 서로 관련된 값이기 때문에 각각의 배열로 선언하기 보다는 하나의 클래스로 정의해 하나의 배열로 다루는 것이 데이터의 무결성(integrity) 측면에서 바람직하기 때문
-
HashMap은 키와 값을 각각 Object 타입으로 저장
키(key) 컬렉션 내의 키 중에서 유일해야 함
값(value) 키와 달리 데이터의 중복을 허용
-
HashMap은 키나 값으로 null를 허용
해싱과 해시함수
- 해싱: 해시함수(hash function)를 이용해서 데이터를 해시테이블(hash table)에 저장하고 검색하는 기법
- 해시함수는 데이터가 저장되어 있는 곳을 알려 주기 때문에 다량의 데이터 중에서도 원하는 데이터를 빠르게 찾을 수 있음
- 해싱을 구현한 컬렉션 클래스로는
HashSet,HashMap,HashTable등이 있음HashTable은 컬렉션 프레임웍이 도입되면서HashMap으로 대체되었으나 호환성 문제로 남겨둠
- 해싱에 사용하는 자료구조는 배열과 링크드 리스트의 조합으로 되어 있음
- 저장할 데이터의 키를 해시함수에 넣으면 배열의 한 요소를 얻게 되고, 다시 그 곳에 연결되어 있는 링크드 리스트에 저장하게 됨
HashMap에 저장된 데이터를 찾는 과정
- 검색하고자 하는 값의 키로 해시함수를 호출함
- 해시함수의 계산결과(해시코드)로 해당 값이 저장되어 있는 링크드 리스트를 찾음
- 링크드 리스트에서 검색한 키와 일치하는 데이터를 찾음
-
하나의 서랍에 많은 데이터가 저장되어 있는 형태보다 많은 서랍에 하나의 데이터만 저장되어 있는 형태가 더 빠른 검색결과를 얻을 수 있음
- 하나의 링크드 리스트(서랍)에 최소한의 데이터만 저장하려면, 저장될 데이터의 크기를 고려해 HashMap의 크기를 적절하게 지정해주어야 함
- 해시함수가 서로 다른 키에 대해 중복된 해시코드의 반환을 최소화해야 함
-
해싱을 구현한 컬렉션 클래스에서는 Object 클래스에 정의된
hashCode()를 해시함수로 사용함- Object 클래스에 정의된
hashCode()는 객체의 주소를 이용하는 알고리즘으로 해시코드를 만들어 냄 - String 클래스의 경우, Object로부터 상속받은
hashCod()를 오버라이딩해서 문자열의 내용으로 해시코드를 만들어 냄. 따라서 서로 다른 String인스턴스일지라도 같은 내용의 문자열을 가졌다면hashCode()를 호출하면 같은 해시코드를 얻음
- Object 클래스에 정의된
- HashSet은 서로 다른 두 객체에 대해
equals()로 비교한 결과가 true인 동시에hashCode()의 반환값이 같아야 같은 객체로 인식 -
HashMap도 같은 방법을 사용해 객체를 구별하며, 이미 존재하는 키에 대한 값을 저장하면 기존의 값을 새로운 값으로 덮어씀
- 새로운 클래스를 정의할 때
equals()를 재정의 오버라이딩해야 한다면hashCod()도 같이 재정의해서equals()의 결과가 true인 두 객체의 해시코드hashCode()의 결과 값이 항상 같도록 해주어야 함- 그렇지 않으면 HashMap과 같이 해싱을 구현한 컬렉션 클래스에서는
equals()의 호출결과가 true이지만 해시코드가 다른 두 객체를 다른 것으로 인식하고 따로 저장할 것 equals()로 비교한 결과가 false이고 해시코드가 같은 경우는 같은 링크드 리스트에 저장된 서로 다른 두 데이터가 됨
- 그렇지 않으면 HashMap과 같이 해싱을 구현한 컬렉션 클래스에서는
4. TreeMap
- TreeMap의 생성자와 메서드
- 이진검색트리의 형태로 키와 값의 쌍으로 이주어진 데이터를 저장
- 검색과 정렬에 적합한 컬렉션 클래스
- HashMap과 TreeMap 중 검색에 관한한 대부분의 경우 HashMap이 TreeMap보다 더 뛰어나므로 HashMap을 사용하는 것이 좋고, 범위검색이나 정렬이 필요한 경우에는 TreeMap을 사용하는 것이 좋음
5. Properties
- Properties의 생성자와 메서드
- Hashtable을 상속받아 구현한 것
- Hashtable은 키와 값을 (Object, Object)의 형태로 저장하는데 비해 Properties는 (String, String) 형태로 저장하는 단순화된 컬렉션 클래스
- 애플리케이션의 환경설정과 관련된 속성을 저장하는데 사용되며 데이터를 파일로부터 읽고 쓰는 기능을 제공
- Properties는 Hashtable을 상속받아 구현한 것이므로 Map이 특성상 저장순서를 유지하지 않음
6. Collections
- 컬렉션과 관련된 메서드를 제공
java.util.Collection은 인터페이스,java.util.Collections는 클래스
컬렉션의 동기화
- 멀티 쓰레드 프로그래밍에서는 하나의 객체를 여러 쓰레드가 동시에 접근할 수 있기 때문에 데이터의 일관성(consistency)을 유지하기 위해서는 공유되는 객체에 동기화(synchronization)이 필요
- ArrayList, HashMap과 같은 컬렉션은 동기화를 자체적으로 처리하지 않고 필요한 경우에만
java.util.Collections클래스의 동기화 메서드를 이용해 동기화 처리가 가능하도록 함synchronized가 붙은 메서드 사용
변경불가 컬렛션 만들기
- 컬렉션에 저장된 데이터를 보호하기 위해 컬렉션을 변경할 수 없게, 읽기전용으로 만들어야 할 때가 있음
- 멀티 쓰레드 프로그래밍에서 여러 쓰레드가 하나의 컬렉션을 공유하다보면 데이터가 손상될 수 있는데, 이를 방지하고자 할 때 사용
unmodifiable이 붙은 메서드 사용
싱클톤 컬렉션 만들기
- 단 하나의 객체만을 저장하는 컬렉션을 만들고 싶은 경우 사용
-
매개변수로 저장할 요소를 지정하면 해당 요소를 저장하는 컬렉션을 반환하고, 반환된 컬렉션은 변경할 수 없음
singleton이 붙은 메서드 사용
한 종류의 객체만 저장하는 컬렉션 만들기
- 컬렉션에 지정된 종류의 객체만 저장할 수 있도록 제한하고 싶을 때 사용
-
checked가 붙은 메서드 사용 - 두 번째 매개변수에 저장할 객체의 클래스를 지정
컬렉션 클래스 정리
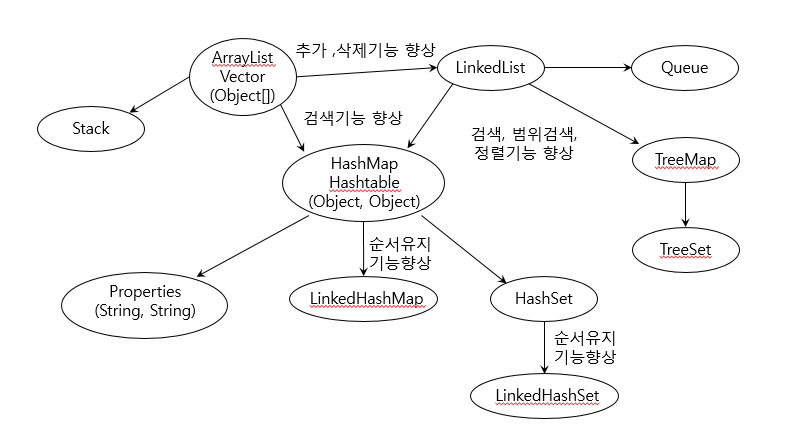
이미지 출처: https://steady-snail.tistory.com/78
| 컬렉션 | 특징 |
|---|---|
| ArrayList | 배열기반, 데이터의 추가와 삭제에 불리, 순차적인 추가삭제는 제일 빠름. 임의의 요소에 대한 접근성(accessibility)이 뛰어남 |
| LinkedList | 연결기반. 데이터의 추가와 삭제에 유리. 임의의 요소에 대한 접근성이 좋지 않음 |
| HashMap | 배열과 연결이 결합된 형태. 추가, 삭제, 검색, 접근성이 모두 뛰어남. 검색에는 최고 성능을 보임 |
| TreeMap | 연결기반. 정렬과 검색에 적합. 검색성능은 HashMap보다 떨어짐 |
| Stack | Vector를 상속받아 구현 |
| Queue | LinkedList가 Queue 인터페이스를 구현 |
| Properties | Hashtable을 상속받아 구현 |
| HashSet | HashMap을 이용해서 구현 |
| TreeSet | TreeMap을 이용해서 구현 |
| LinkedHashMap LinkedHashSet |
HashMap과 HashSet에 저장순서 유지기능 추가 |
Chapter 11 끝!!!