Chapter 14. 람다와 스트림_2(스트림)
04 Feb 2022 | 자바의 정석 JAVA2. 스트림(stream)
2.1 스트림이란?
- 스트림(Stream): 데이터 소스를 추상하하고, 데이터를 다루는데 자주 사용되는 메서드들을 정의
- 데이터 소스를 추상화하였다는 것은 데이터 소스가 무엇이던 간에 같은 방식으로 다룰 수 있게 되었다는 것과 코드의 재사용성이 높아진다는 것을 의미
-
스트림을 이용하면 배열이나 컬렉션뿐만 아니라 파일에 저장된 데이터도 모두 같은 방식으로 다룰 수 있음
-
예시
-
문자열 배열과 같은 내용의 문자열을 저장하는 List가 있을 때
String[] strArr = {"aaa", "ddd", "ccc"}; List<String> strLisst = Arrays.asList(strArr); -
두 데이터 소스를 기반으로 하는 스트림은
Stream<String> strStream1 = strList.stream(); Stream<String> strStream2 = Arrays.stream(strArr); -
두 스트림으로 데이터소스의 데이터를 읽어 정렬하고 화면에 출력하는 방법
// 기존 방법 Arrays.sort(strArr); Collections.sort(strList); for (String str : strArr) System.out.println(str); for (String str : strList) System.out.println(str); // 스트림 사용 strStream1.sorted().forEach(Ststem.out::println); strStream2.sorted().forEach(Ststem.out::println);
-
스트림은 데이터 소스를 변경하지 않음
-
스트림은 데이터 소스로부터 데이터를 읽기만할 뿐, 데이터 소스를 변경하지 않음
-
정렬된 결과를 컬렉션이나 배열에 담아 반환할 수도 있음
// 정렬된 결과를 샐로운 List에 담아서 반환 List<String> sortedList = strStream2.sorted().collect(Collectors.toLost());
스트림은 일회용
- Iterator처럼 일회용. Iterator로 컬렉션의 요소를 모두 읽고 나면 다시 사용할 수 없는 것처럼, 스트림도 한번 사용하면 닫혀서 다시 사용할 수 없음
- 필요하다면 스트림을 다시 생성해야 함
스트림은 작업을 내부 반복으로 처리
- 내부 반복은 반복문을 메서드의 내부에 숨길 수 있다는 것을 의미
forEach()는 스트림에 정의된 메서드 중의 하나로 매개변수에 대입된 람다식을 데이터 소스의 모든 요소에 적용
스트림의 연산
-
스트림이 제공하는 다양한 연산을 이용해 복잡한 작업들을 간단히 처리할 수 있음
- 연산(operation): 스트림에 정의된 메서드 중에서 데이터 소스를 다루는 작업을 수행하는 것
-
스트림이 제공하는 연산은 중간 연산과 최종 연산으로 분류
중간 연산 연산 결과가 스트림인 연산. 스트림에 연속해서 중간 연산할 수 있음
최종 연산 연산 결과가 스트림이 아닌 연산. 스트림의 요소를 소모하므로 단 한번만 가능
지연된 연산
- 최종 연산이 수행되기 전까지는 중간 연산이 수행되지 않는다는 것
- 스트림에 대해
distinct()나sort()같은 중간 연산을 호출해도 즉각적인 연산이 수행되는 것은 아님- 중간 연산을 호출하는 것은 어떤 작업이 수행되어야하는지를 지정해주는 것일 뿐
- 최종 연산이 수행되어야 스트림의 요소들이 중간 연산을 거쳐 최종 연산에서 소모됨
**Stream
- 요소의 타입이 T인 스트림은 기본적으로 Steam
이지만, 오토박싱&언박싱으로 인한 비효율을 줄이기 위해 데이터 소스의 요소를 기본형으로 다루는 스트림을 제공 - IntStream, LongStream, DoubleStream이 제공됨
- Stream
대신 IntStream을 사용하는 것이 더 효율적. IntStream은 int 타입의 값으로 작업하는데 유용한 메서드들이 포함되어 있음
병렬 스트림
-
스트림으로 데이터를 다룰 경우 병렬 처리가 쉬움
-
병렬 스트림은 내부적으로 fork&join 프레임웍을 이용해 자동적으로 연산을 병렬로 수행
-
스트림에
parallel()이라는 메서드를 호출해 병렬로 연산을 수행하도록 지시- 병렬로 처리되지 않게 하려면
sequential()을 호출하면 됨 -
모든 스트림은 기본적으로 병렬 스트림이 아니므로
sequential()을 호출할 필요가 없음 sequential()은parallel()을 호출한 것을 취소할 때만 사용
- 병렬로 처리되지 않게 하려면
2.2 스트림 만들기
컬렉션
-
컬렉션의 최고 조상인 Collection에
stream()이 정의되어 있음- Collection의 자손인 List와 Set을 구현한 컬렉션 클래스들은 모두 이 메서드로 스트림 생성 가능
-
stream()은 해당 컬렉션을 소스(source)로 하는 스트림을 반환Stream<T> Collection.stream() -
List로부터 스트림을 생성하는 코드
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5); // 가변인자 Stream<Integer> intstream = list.stream(); // list를 소스로 하는 컬렉션 생성 -
forEach(): 지정된 작업을 스트림의 모든 요소에 대해 수행intStream.forEach(System.out::println); // 스트림의 모든 요소를 출력 intStream.forEach(System.out::println); // 에러. 스트림이 이미 닫힘forEach()는 스트림의 요소를 소모하면서 작업을 수행하므로 같은 스트림에forEach()를 두 번 호출할 수 없음- 스트림의 요소를 한번 더 출력하려면 스트림을 새로 생성해야 함
forEach()에 의해 스트림의 요소가 소모되는 것이지, 소스의 요소가 소모되는 것은 아니기 때문에 같은 소스로부터 다시 스트림을 생성할 수 있음
배열
-
배열을 소스로 스트림을 생성하는 메서드는 Stream과 Arrays에 static 메서드로 정의되어 있음
Stream<T> Stream.of(T... values) // 가변인자 Stream<T> Stream.of(T[]) Stream<T> Arrays.stream(T[]) Stream<T> Arrays.stream(T[] array, int startInclusive, int endExclusive) -
int, long, double과 같은 기본형 배열을 소스로 하는 스트림을 생성하는 메서드
IntStream IntStream.of(int... values) // Stream이 아니라 IntStream IntStream IntStream.of(int[]) IntStream Arrays.stream(int[]) IntStream Arrays.stream(int[] array, int startInclusive, int endExclusive)
특정 범위의 정수
-
IntStream과 LongStream은 지정된 범위의 연속된 정수를 스트림으로 생성해 반환하는
range()와rangeClosed()를 가짐IntStream IntStream.range(int begin, int end) IntStream IntStream.rangeClosed(int begin, int end)range()의 경우 경계의 끝인 end가 범위에 포함되지 않고,rangeClosed()의 경우 포함됨- int보다 큰 범위의 스트림을 생성하려면 LongStream에 있는 동일한 이름의 메서드를 사용하면 됨
임의의 수
-
난수를 생성하는데 사용하는 Random 클래스에 포함된 인스턴스 메서드
IntStream ints() LongStream longs() DoubleStream doubles()-
해당 타입의 난수들로 이루어진 스트림을 반환
-
반환하는 스트림은 크기가 정해지지 않은 ‘무한 스트림(infinite stream)’이므로
limit()도 함께 사용해 스트림의 크기를 제한해주어야 함 -
limit()은 스트림의 개수를 지정하는데 사용되며, 무한 스트림을 유한 스트림으로 만들어 줌IntStream intStream = new Random().ints(); // 무한 스트림 intStream.limit(5).forEach(System.out::println) // 5개의 요소만 출력 -
매개변수로 스트림의 크기를 지정해 유한 스트림을 생성해 반환할수도 있음
-
매개변수로 범위를 지정해줄 수 있음. 단 end는 범위에 포함되지 않음
-
람다식 - iterate(), generate()
-
Stream 클래스이
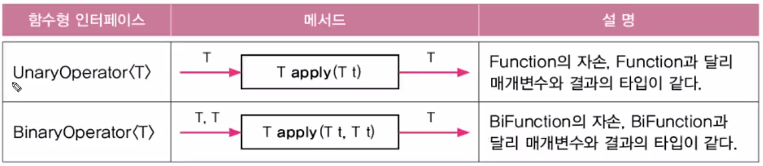
iterate()와generate()는 람다식을 매개변수로 받아, 람다식에 의해 계산되는 값들을 요소로 하는 무한 스트림을 생성static <T> Stream<T> iterate(T seed, UnaryOperator<T> f) static <T> Stream<T> generate(Supplier<T> s)iterate()는 seed로 지정된 값부터 시작해, 람다식 f에 의해 계산된 결과를 다시 seed값으로 해서 계산을 반복generate()는 람다식에 의해 계산되는 값을 요소로 하는 무한 스트림을 생성해 반환하지만, 이전 결과를 이용해 다음 요소를 계산하지 않음
-
generate()에 정의된 매개변수 타입은Supplier<T>이므로 매개변수가 없는 람다식만 허용
파일
-
java.nio.file.Files는 파일을 다루는데 필요한 유용한 메서드들을 제공
-
list()는 지정된 디렉터리에 있는 파일의 목록을 소스로 하는 스트림을 생성해서 반환Stream<Path> Files.list(Path dir) -
파일의 한 행을 요소로 하는 스트림을 생성하는 메서드
Stream<String> Files.lines(Path path) Stream<String> Files.lines(Path path, Charset cs) Stream<String> lines() // BufferedReader 클래스의 메서드
빈 스트림
-
요소가 하나도 없는 비어있는 스트림 생성 가능
-
스트림에 연산을 수행한 결과가 하나도 없을 때, null보다는 빈 스트림을 반환하는 것이 나음
Stream emptyStream = Stream.empty(); // empty()는 빈 스트림을 생성해 반환 long count = emptyStream.count(); // count 값은 0count(): 스트림 요소의 개수를 반환
두 스트림의 연결
-
Stream의 static 메서드인
concat()을 사용하면, 두 스트림을 하나로 연결할 수 있음- 연결하려는 두 스트림의 요소는 같은 타입이어야 함
String[] str1 = {"123", "456"}; String[] str2 = {"AAA", "BBB"}; Stream<String> strs1 = Stream.of(str1); Stream<String> strs2 = Stream.of(str2); Stream<String> str3 = Stream.concat(strs1, strs2); // 두 스트림을 하나로 연결
2.3 스트림의 중간연산
스트림 자르기 - skip(), limit()
Stream<T> skip(long n)
Stream<T> limit(long maxSize)
-
skip()은 처음 n개의 요소를 건너뛰고, limit()는 스트림의 요소를 5개로 제한
IntStream intStream = IntStream.rangeClosed(1, 10); // 1~10의 요소를 가진 스트림 intStream.skip(3).limit(5).forEach(System.out::println); // 45678
스트림의 요소 걸러내기 - filter(), distinct()
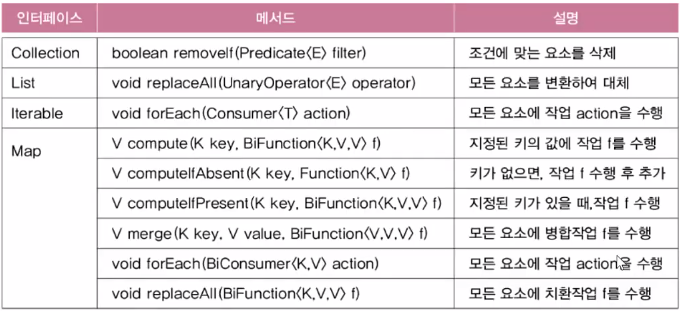
- distinct()는 스트림에서 중복되는 요소들을 제거하고, filter()는 주어진 조건(Predicate)에 맞지 않는 요소를 걸러냄
- filter()는 매개변수로 Predicate를 필요로 하는데, 연산결과가 boolean인 람다식을 사용해도 됨
- 필요하다면 filter()을 다른 조건으로 여러 번 사용할 수도 있음
정렬 - sorted()
Stream<T> sorted()
Stream<T> sorted(Comparator<? super T> comparator)
- 지정된 Comparator로 스트림을 정렬하는데, Comparator 대신 int 값을 반환하는 람다식을 사용하는 것도 가능
- Comparator을 지정하지 않으면 스트림 요소의 기본 정렬 기준(Comparable)로 정렬
- 단, 스트림의 요소가 Comparable을 구현한 클래스가 아니면 예외 발생
- Comparator인터페이스의 static 메서드
변환 - map()
Stream<R> map(Function<? super T, ? extends R> mapper)
- 스트림의 요소에 저장된 값 중에서 원하는 필드만 뽑아내거나 특정 형태로 변환해야 할 경우 사용
- 매개변수로 T타입을 R타입으로 변환해서 반환하는 함수를 지정해야 함
- map()은 중간연산이므로, 연산결과는 String을 요소로하는 스트림
- map()도 하나의 스트림에 여러 번 적용 가능
조회 - peek()
- 연산과 연산 사이에 올바르게 처리되었는지 확인할 때 사용
- forEach()와 다르게 스트림의 요소를 소모하지 않으므로 연산 사이에 여러 번 끼워 넣어도 괜찮음
- filter()나 map()의 결과를 확인할 때 유용하게 사용됨
mapToInt(), mapToLong(), mapToDouble()
-
map()은 연산의 결과로 Stream
타입의 스트림을 반환하는데, 스트림의 요소를 숫자로 변환하는 경우 IntStream과 같은 기본형 스트림으로 변환하는 것이 더 유용함 -
mapToInt()를 사용해 Stream
가 아닌 IntStream 타입의 스트림을 생성 가능 -
count()만 지원하는 Stream
와 달리 기본형 스트림은 숫자를 다루는데 편리한 메서드들을 제공 int sum() // 스트림의 모든 요소의 총합 OptionalDouble average() // sum() / (double) count() OptionalInt max() // 스트림의 요소 중 제일 큰 값 OptionalInt min() // 스트림의 요소 중 제일 작은 값- 이 메서드들은 최종연산이므로 호출 후에 스트림이 닫힘
- sum()과 average()를 모두 호출해야할 때, 스트림을 또 생성해야하는 불편함을 없애기 위해 summaryStatistics()라는 메서드를 제공
2.4 Optional와 OptionalInt
- Optional
은 지네릭 클래스로 'T타입의 객체'를 감싸주는 래퍼 클래스 - Optional 타입의 객체에는 모든 타입의 참조변수를 담을 수 있음
- 최종 연산 결과를 Optional 객체에 담아서 반환
- 객체에 담아서 반환하면, 반환된 결과가 null인지 if문으로 체크하는 대신 Optional 에 정의된 메서드를 통해 간단히 처리할 수 있음
Optional 객체 생성하기
- of() 또는 ofNullable()을 사용
- of()는 매개변수의 값이 null이면 NullPointerException이 발생
- 참조변수의 값이 null일 가능성이 있으면, of()대신 ofNullable() 사용
- Optinal
타입의 참조변수를 기본값으로 초기화할 때는 empty()를 사용
Optional 객체의 값 가져오기
- 값을 가져올 때는 get()을 사용
- 값이 null일 경우 NoSuchElementException이 발생하며, 이를 대비해 orElse()로 대체 값을 지정할 수 있음
- orElse()의 변형으로 null 값을 대체할 값을 반환하는 람다식을 지정할 수 있는 orElseGet()과 null일 때 지정된 예외를 발생시키는 orElseThrow()가 있음
- Optional 객체에도 filter(), map(), flatmap() 사용 가능
- 만약 Optional 객체 값이 null인 경우 이 메서드들은 아무 일도 하지 않음
- isPresent()는 Optional 객체의 값이 null이면 false를, 아니면 true를 반환
ifPresent(Consumer<T> block)은 값이 있으면 주어진 람다식을 실행하고, 없으면 아무 일도 하지 않음- Optional
를 반환하는 findAny()나 findFirst()와 같은 최종 연산과 잘 어울림
- Optional
OptionalInt, OptionalLong, OptionalDouble
- 반환 타입이 Optional
가 아닌 것을 제외하면 Stream에 정의된 것과 비슷
2.5 스트림의 최종 연산
- 최종 연산은 스트림의 요소를 소모해서 결과를 만들어내기 때문에 최종 연산 후에는 스트림이 닫히게 되고 더 이상 사용할 수 없음
- 최종 연산의 결과는 단일 값이거나, 스트림의 요소가 담긴 배열 또는 컬렉션일 수 있음
forEach()
- 반환 타입이 void이므로 스트림의 요소를 출력하는 용도로 많이 사용
조건 검사 - allMatch(), anyMatch(), noneMatch(), findFirst(), findAny()
- 스트림의 요소에 대해 지정된 조건에 모든 요소가 일치하는지, 일부가 일치하는지 아니면 어떤 요소도 일치하지 않는지 확인하는데 사용하는 메서드
- 메서드들은 모두 매개변수로 Predicate를 요구하며, 연산결과로 boolean을 반환
- findFirst()는 스트림의 요소 중에서 조건에 일치하는 첫 번째 것을 반환
- 주로 filter()와 함께 사용되어 조건에 맞는 스트림의 요소가 있는지 확인하는데 사용됨
- 병렬 스트림인 경우 findFirst() 대신 findAny()를 사용
- findAny()와 findFirst()의 반환 타입은 Optional
이며, 스트림의 요소가 없을 때는 비어있는 Optional 객체를 반환
통계 - count(), sum(), average(), max(), min()
-
기본형 스트림의 요소들에 대한 통계 정보를 얻을 수 있는 메서드
-
기본형 스트림이 아닌 경우 통계와 관련된 메서드는 아래 3개뿐
long count() Optional<T> max(Comparator<? super T> comparator) Optional<T> min(Comparator<? super T> comparator)
리듀싱 - reduce()
- 스트림의 요소를 줄여나가면서 연산을 수행하고 최종결과를 반환하기 때문에 매개변수의 타입이 BinaryOperator
인 것 - 처음 두 요소를 가지고 연산한 결과를 가지고 그 다음 요소와 연산
- 이 과정에서 스트림의 요소를 하나씩 소모하게 되고, 스트림의 모든 요소를 소모하게 되면 그 결과를 반환
- 연산결과의 초기값(indentity)을 갖는 reduce()도 존재
- 초기값과 스트림의 첫 번째 요소로 연산을 시작
- 스트림의 요소가 하나도 없는 경우, 초기값이 반환되므로, 반환 타입이 Optional
가 아니라 T
- reduce()를 사용하기 위해 초기값(identity)과 어떤 연산(BinaryOperator)으로 스트림의 요소를 줄여나갈 것이지만 결정하면 됨
2.6 collect()
- collect()는 스트림의 요소를 수집하는 최종 연산으로 reducing()과 유사
- collect()가 스트림의 요소를 수집하기 위해서는 어떻게 수집할 것인가에 대한 방법이 정의되어 있어야 하는데, 이 방법을 정의한 것이 컬렉터(collector)
- 컬렉터는 Collector 인터페이스를 구현한 것. 직접 구현할 수도 있고 미리 작성된 것을 사용할 수도 있음
- Collectors 클래스는 미리 작성된 다양한 종류의 컬렉터를 반환하는 static 메서드를 가지고 있음
collect() 스트림의 최종연산, 매개변수로 컬렉터를 필요로 함
Collector 인터페이스, 컬렉터는 이 인터페이스를 구현해야 함
Collectors 클래스, static 메서드로 미리 작성된 컬렉터를 제공
- collect()는 매개변수의 타입이 Collector
- 매개변수가 Collector를 구현한 클래스의 객체이어야 한다는 의미
- collect()는 이 객체에 구현된 방법대로 스트림의 요소를 수집
스트림을 컬렉션과 배열로 변환
- 스트림의 모든 요소를 컬렉션에 수집하려면 Collectors 클래스의 toList()와 같은 메서드를 사용하면 됨
- List나 Set이 아닌 특정 컬렉션을 지정하려면, toCollection()에 해당 컬렉션의 생성자 참조를 매개변수로 넣어주면 됨
- Map은 키와 값의 쌍으로 저장해야하므로 객체의 어떤 필드를 키로 사용할지와 값으로 사용할지를 지정해줘야 함
- 스트림에 저장된 요소들을 ‘T[]’ 타입의 배열로 변환하려면, toArray()를 사용하면 됨
- 단, 해당 타입의 생성자 참조를 매개변수로 지정해줘야 함
- 만일 매개변수를 지정하지 않으면 반환되는 타입은 ‘Object[]’
문자열 결합 - joining()
- 문자열 스트림의 모든 요소를 하나의 문자열로 연결해서 반환
- 구분자와 접두사, 접미사 지정 가능
- 스트림의 요소가 String이나 StringBuffer처럼 CharSequence의 자손인 경우에만 결합이 가능
- 스트림의 요소가 문자열이 아닌 경우 먼저 map()을 이용해서 스트림의 요소를 문자열로 변환해야 함
- map()없이 스트림에 바로 joining()하면, 스트림의 요소에 toString()을 호출한 결과를 결합
그룹화와 분할 - groupingBy(), partitioningBy()
- 그룹화: 스트림의 요소를 특정 기준으로 그룹화하는 것을 의미
-
분할: 스트림의 요소를 지정된 조건에 일치하는 그룹과 일치하지 않는 그룹으로의 분할을 의미
- groupingBy()는 스트림의 요소를 Function으로, partitioningBy()는 Predicate로 분류
- 그룹화와 분할의 결과는 Map에 담겨 반환됨
2.7 Collector 구현하기
-
컬렉터를 작성한다는 것은 Collector 인터페이스를 구현한다는 것을 의미
-
Collector 인터페이스 정의
public interface Collector<T, A, R> { Supplier<A> supplier(); Biconsumer<A, t> accumulator(); BinaryOperator<A> combiner(); Fynction<A, R> finisher(); Set<Characteristics> characteristics(); // 컬렉터의 특성이 담긴 Set을 반환 ... }- 직접 구현해야하는 것은 위의 5개 메서드
- chracteristics()를 제외하면 모두 반환 타입이 함수형 인터페이스. 즉, 4개의 람다식을 작성하면 됨
supplier() 작업 결과를 저장할 공간을 제공
accumulator() 스트림의 요소를 수집(collect)할 방법을 제공
combiner() 두 저장공간을 병합할 방법을 제공 (병렬 스트림)
finisher() 결과를 최종적으로 변환할 방법을 제공
- supplier()는 수집 결과를 저장할 공간을 제공하기 위한 것
- accumulatoer()는 스트림의 요소를 어떻게 supplier()가 제공한 공간에 누적할 것인지를 정의
- combiner()는 병렬 스트림인 경우, 여러 쓰레드에 의해 처리된 결과를 어떻게 합칠 것인가를 정의
- finisher()는 작업결과를 변환하는 일을 하는데 변환이 필요없다면, 항등 함수인 Function.identity()를 반환하면 됨
Characteristics.CONCURRENT 병렬로 처리할 수 있는 작업
Characteristics.UNORDERED 스트림의 요소의 순서가 유지될 필요가 없는 작업
Characteristics.IDENTITY_FINISH finisher()가 항등 함수인 작업
- characteristtics()는 컬렉터가 수행하는 작업의 속성에 대한 정보를 제공하기 위한 것
- 3가지 속성 중 해당하는 것을 Set에 담아 반환하도록 구현
- 아무런 속성도 지정하고 싶지 않다면 비어있는 Set을 반환
Chapter 14 끝!!!
.png)